

トマトの画像を収穫時期別にセマンティックセグメンテーションしていくタスクを紹介します。Segmentation modelsを用いて収穫時期にラベル付けした多クラスの分類していきます。
Segmentation modelsはTensorFlow==1.13を推奨していますが、今回はSegmentation modelsのコードをアップグレードしてTensorFlow2.6環境で実装していこうと思います。
2値分類については過去の記事で紹介していますので、よかったら併せてご覧ください↓。

学習環境
ローカル環境でGPUをつかって実装していきます。CUDA toolkit関連セットアップが分からない場合はこのサイトに細かく掲載されていますので確認してみてください。
PC環境
- OS : Windows 10
- CPU : AMD Ryzen7 5800
- メモリ : 16GB
- GPU : GeForce RTX3070 8GB
CUDA関連
- CUDA : 11.4
- cuDNN:8.2
Python
- Python 3.7.10
ライブラリ
- tensorflow-gpu 2.6.0
- tensorflow-estimator 2.6.0
- tensorboard 2.6.0
- image-classifiers 1.0.0
- efficientnet 1.0.0
- その他必要に応じて
Segmentation modelsのコードをTensorFlow2へアップグレードする
アップグレードやり方を説明していきます。
- Githubよりsegmentation modelsのソースコード↓をダウンロードしてください。ダウンロードしたらデスクトップへ解凍してください。
- TensorFlow2.xをインストールした環境をアクティベートして↓のコードをAnacondaPromtなどで実行してください。保存するディレクトリをあらかじめつくらないように注意してください。
# segmentation_modelsをデスクトップへ置いた場合の例
cd desktop
tf_upgrade_v2 --intree segmentation_models --outtree segmentation_models_tf2 --reportfile report.txt実行するとsegmentation_models_tf2というディレクトリが生成されると思います。ここを作業ディレクトリとしてつかっていきます。
アップグレードは別記事で紹介していますので詳しくは↓をご覧ください。

データセットの準備
独自のトマト画像へアノテーションしていきます。データセットの準備手順は↓です。
- 独自の画像を用意
- labelmeでアノテーションしてjsonファイルを作成
- jsonファイルをセマンティックセグメンテーション用のデータセットへ変換
labelmeは↓からダウンロードしてください。上記処理に必要となります。
labelmeでアノテーションしてjsonファイルを作成
labelmeのつかい方、jsonファイルの作成は↓に詳細がありますのでご覧ください。

今回のラベルは↓にしています。
- 完熟した収穫時期 : A
- もう少ししたら収穫時期 : B
- 未熟 : C
jsonファイルをセマンティックセグメンテーション用のデータセットへ変換
セマンティックセグメンテーション用のデータセットであるラベリングしたpngファイルをつくっていきます。↓のようなペア画像です。


- まずはimgデータ(.jpg)とアノテーションデータ(.json)ファイルをlabelmeの↓ディレクトリへ格納してください。
labelme
-> examples
-> semantic_segmentation
-> train #名前は任意です
1.jpg
1.json
2.jpg
2.json
3.jpg
3.json
...
- semantic_segmentationディレクトリ下にlabet.txtというファイルがあると思います。これをアノテーションした内容へ変換します。今回の場合は↓になります。label.txtを↓へ書き換えて保存すればOKです 。labelmeでラベリングするときに生成されたモノでもOKです。
__ignore__ _background_ A B C
- AnacondaPromptなどで↓のコードを実行してください。
cd Desktop/labelme/examples/semantic_segmentation #labelmeをデスクトップへ保存した場合
python labelme2voc.py train data_dataset --labels labels.txt実行すると変換が始まり、data_datasetというディレクトリが生成されると思います。中に「JPEGImage」「SegmentationClassPNG」が入っていればOKです。data_datasetディレクトリを segmentation_models_tf2 /dataディレクトリへ↓のように移動してください。
segmentation_models_tf2
-> data
-> data_dataset
以上で準備は完了です。
アノテーションデータ(.png)について少し説明
データの準備とは関係ありませんが、多クラスのセマンティックセグメンテーションを実施するために、なぜアノテーションデータ(.png)が必要になるか簡単に説明します。
実はアノテーションデータは.pngで出力することに意味があります。このアノテーションデータはインデックスカラーをつかって作成されています。
インデックスカラーとは色が順番に並んだテーブルのようになっています。0:黒、1:赤、2:緑のような形で表現されています。この先でも説明しますが.pngデータをインデックスカラーで読み込むことでクラス分けできる仕組みになっています。
↓に詳しく説明されています。興味ある方はご覧ください。

セマンティックセグメンテーションの実装
いよいよ実装していきます。全コードは一番↓に記載します。ポイントをピックアップして説明します。
- フレームワークを
keras=> tf.kerasで動かす
Segmentation modelsはデフォルトでkerasフレームワークをつかおうとしますが旧バージョンのkerasでしか上手く動かないので、TensorFlowに組み込まれたtf.kerasで動かします。↓のコードを入れればOKです。
import segmentation_models as sm
sm.set_framework('tf.keras')
sm.framework()- 教師データを”パレットモード”へ変換しインデックスカラーフォーマットとする
.pngファイルのインデックスカラーを利用しクラス分類するため次のコードでデータ変換します。
dir ="./data/data_dataset/SegmentationClassPNG"
files = glob.glob(dir+"/*.png")
for i, file in enumerate(files):
image = Image.open(file) #画像の読み込み
image = image.convert("P") #パレットモード(インデックスカラー)へ変換- データの可視化を必ずやっておく
多クラスのセマンティックセグメンテーションを実施する場合、教師データ(Y_train)のデータ形状が↓の感じになり、そのままでは可視化ができません。
Y_train.shape
(***, 320, 224, 4)
きっちり教師データ(マスク)が作成されているか↓のコードで確認しましょう。Segmentation modelsのexampleコードです。
def visualize(**images):
n = len(images)
plt.figure(figsize=(32, 16))
for i, (name, image) in enumerate(images.items()):
plt.subplot(1, n, i + 1)
plt.xticks([])
plt.yticks([])
plt.title(' '.join(name.split('_')).title())
plt.imshow(image)
plt.show()
i = 0 #何枚目の画像を確認するか変更できます
mask = Y_train[i] # get some sample
visualize(
image=X_train[i],
background_mask_mask=mask[..., 0].squeeze(),
A_mask=mask[..., 1].squeeze(),
B_mask=mask[..., 2].squeeze(),
C_mask=mask[..., 3].squeeze(),
)ここできちんと狙い通りマスクされているかクラスとマスクを照らし合わせて確認してください。

- 損失関数LossでDice係数/metricsでIoUを使用
多クラス分類の場合、通常はCategoricalCrossEntropyを用いると思いますが、セマンティックセグメンテーションではDice係数がよく用いられます。今回はDice係数を使用しています。
また評価指標としてはIoUを選択しています。CNNではAccuracyをつかうと思いますが、セマンティックセグメンテーションでAccuracyをつかうとすぐに100%付近まで精度が出てしまうので評価できません。IoUをつかうのが一般的です。コードは↓です。
dice_loss = sm.losses.DiceLoss()
metrics = [sm.metrics.IOUScore(threshold=0.5)]
model.compile(optimizer=opt, loss=dice_loss, metrics=metrics) Dice係数、IoUは↓のサイトに詳しく記載されていました。併せてご覧ください。
- 学習条件
- セマンティックセグメンテーションモデル:U-Net
- バックボーン:Efficient Net B7
- 学習済み重み:imagenet
- Optimiser : Adam(learning_rate=1e-3)
- Batch_size : 1
- epochs : 100
学習結果
学習曲線は↓の感じです。
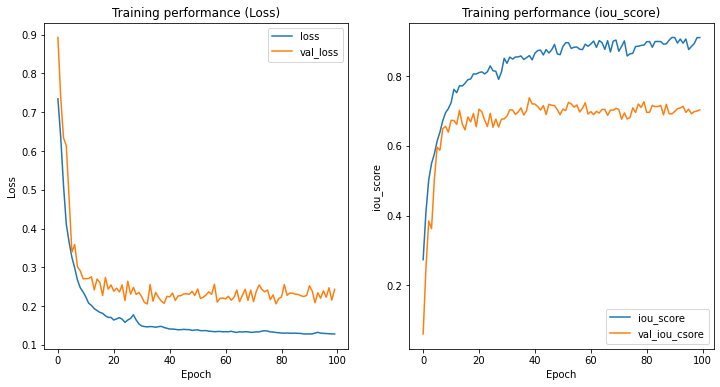
学習はうまく進んだと思います。Lossグラフより10エポックくらいから過学習気味になっていると思います。
セマンティックセグメンテーションはよく過学習します。一般的には画像枚数を増やして対応するのが良いのですが、私の経験ではある程度過学習しても学習を継続する方がいいです。学習を早くやめてしまうとノイズだらけで使いモノになりませんが、一方である程度過学習してても使えることがおおいです。ですが学習をやりすぎると汎用性が落ちますので、この辺りのさじ加減はCNNよりも難しいです。
結果を可視化します。見づらくてすみませんが、左3つのマスク画像が正解ラベル、右3つがセマンティックセグメンテーションモデルによる予測結果です。そこそこいい感じのモノになったのではないでしょうか。



皆さんも試してみてください。良いディープラーニングライフを👍
全コード
今回実装したコードを載せておきます。参考にしてください。
学習データセット
#ライブラリインポート
import tensorflow as tf
import segmentation_models as sm
sm.set_framework('tf.keras')
sm.framework()
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import numpy as np
import matplotlib.pyplot as plt
import glob
from PIL import Image
from tensorflow.python.keras.utils import np_utils
from sklearn.model_selection import train_test_split
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#データセット
x_image_size = 224 #インプット画像のサイズ
y_image_size = 320 #インプット画像のサイズ
X = []
Y = []
#画像データ
dir ="./data/data_dataset/JPEGImages"
files = glob.glob(dir+"/*.jpg")
for i, file in enumerate(files):
image = Image.open(file) #画像の読み込み
image = image.convert("RGB") #RGBに変換
image = image.resize((x_image_size, y_image_size)) #サイズ変更
data = np.asarray(image) #画像データを配列へ変更
X.append(data) #画像データを繰返し追加
X = np.array(X)
#アノテーションデータ(マスクデータ)
dir ="./data/data_dataset/SegmentationClassPNG"
files = glob.glob(dir+"/*.png")
for i, file in enumerate(files):
image = Image.open(file) #画像の読み込み
image = image.convert("P") #パレットモード(インデックスカラー)へ変換
image = image.resize((x_image_size, y_image_size)) #サイズ変更
data = np.asarray(image) #画像データを配列へ変更
Y.append(data) #画像データを繰返し追加
Y= np_utils.to_categorical(Y,4)
X_train, X_valid, Y_train, Y_valid = train_test_split(X, Y , test_size=0.2)教師データの可視化
def visualize(**images):
n = len(images)
plt.figure(figsize=(32, 16))
for i, (name, image) in enumerate(images.items()):
plt.subplot(1, n, i + 1)
plt.xticks([])
plt.yticks([])
plt.title(' '.join(name.split('_')).title())
plt.imshow(image)
plt.show()
i = 0 #何枚目の画像を確認するか変更できます
mask = Y_train[i] # get some sample
visualize(
image=X_train[i],
background_mask_mask=mask[..., 0].squeeze(),
A_mask=mask[..., 1].squeeze(),
B_mask=mask[..., 2].squeeze(),
C_mask=mask[..., 3].squeeze(),
)セマンティックセグメンテーションモデルの定義
BACKBORN = 'efficientnetb7'
preprocess_input = sm.get_preprocessing(BACKBORN)
model = sm.Unet(BACKBORN,
encoder_weights='imagenet',
classes = 4,
encoder_freeze = True,
input_shape=(320, 224, 3))
#Dice係数/IoU
opt = tf.keras.optimizers.Adam(learning_rate=1e-3)
dice_loss = sm.losses.DiceLoss()
metrics = [sm.metrics.IOUScore(threshold=0.5)]
model.compile(optimizer=opt, loss=dice_loss, metrics=metrics)
#チェックポイント作成
checkpoint_filepath = './tmp/checkpoint'
model_checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath,
save_weights_only=True,
monitor='val_iou_score',
mode='max',
save_best_only=True)
#学習
history =model.fit(X_train, Y_train, batch_size=1, epochs=100,
validation_data=(X_valid, Y_valid),
callbacks=[model_checkpoint_callback])結果の可視化
#学習曲線
score = model.evaluate(X, Y, verbose=0)
print("evaluate loss: {0[0]}\nevaluate acc: {0[1]}".format(score))
fig, ax = plt.subplots(1, 2, figsize=(12, 6))
ax[0].set_title('Training performance (Loss)')
ax[0].plot(history.epoch, history.history['loss'], label='loss')
ax[0].plot(history.epoch, history.history['val_loss'], label='val_loss')
ax[0].set(xlabel='Epoch', ylabel='Loss')
ax[0].legend()
ax[1].set_title('Training performance (iou_score)')
ax[1].plot(history.epoch, history.history['iou_score'], label='iou_score')
ax[1].plot(history.epoch, history.history['val_iou_score'], label='val_iou_csore')
ax[1].set(xlabel='Epoch', ylabel='iou_score')
ax[1].legend(loc='best')#予測結果の可視化
n = 3 #結果の表示数
ids = np.random.choice(np.arange(len(X_valid)), size=n)
for i in ids:
image = X_valid[i]
gt_mask = Y_valid[i]
image = np.expand_dims(image, axis=0)
pr_mask = model.predict(image)
visualize(
image=image.squeeze(),
A_Ground_Truth=gt_mask[..., 1].squeeze(),
B_Ground_Truth=gt_mask[..., 2].squeeze(),
C_Ground_Truth=gt_mask[..., 3].squeeze(),
#background_mask=pr_mask[..., 0].squeeze(),
A_Prediction=pr_mask[..., 1].squeeze(),
B_Prediction=pr_mask[..., 2].squeeze(),
C_Prediction=pr_mask[..., 3].squeeze(),
)関連図書
↓の本を読んでディープラーニングを勉強しました。ご参考に👍
コメント