

画像分類といえば畳み込みニューラルネットワーク(CNN)が有名ですが、畳み込みを使わない手法としてVision Transformer(通称:ViT)があります。ViTは画像認識の分野で革命的な技術と言われており、CNNの手法を凌いでSoTA(State-of-the-Art)を達成してます。どんなもんか使ってみようと思います。
使ってみての感想は?
画像分類系のアルゴリズムをいろいろ触っている私が実際に使ってみての感想。「精度」「学習速度」は他のCNNモデルと比較してかなりいい!!と思います。一方で「ガンガン過学習する」ような感じもあり、学習データセットの準備やData augmentationはしっかりやった方が良さそうな感じです。メリット・デメリットありますが、Pre-trained model(過去に大量データで学習したモデル)をファインチューニングしたときの威力は半端ないので、迷ったらとにかく使ってみるのが良いと思います👍
今回はvit-pytorchのexamplesをベースに実装を進めていきます。examplesではファインチューニングをしない状態で実装しているのでvalidation accuracy : 0.69程度となっていますが、ファインチューニングするとvalidation accuracy : 0.99 のぶっ飛んだ精度になります。そのやり方を説明していきます。
ファインチューニング??という方はここを参考にしてください↓

独自のデータセットでのViTモデルの実装もやってみました。良かったら併せてご覧ください。

Vision Transformerについて
ViTについて簡単に説明していきます。実装を急ぎたい方はスキップしてください。
ViTは「Transformer」と言われる自然言語処理分野でのSoTAを達成しているモデルを応用しています。なのでTransformerを理解する必要があるのですが、これが結構難しいです。
Transformerについては、Alcia先生の動画がめちゃ分かりやすく説明されているので是非見て下さい。私にはこれ以上の説明はできないと思います。。。
Transformerは文章を単語に分割→それぞれの単語に対し類似度をつかってベクトル化することで重みを表現しています。この「文章」の部分を「画像」へ、「単語」を画像を切り出した「パッチ」へ置き換えてと表現するとViTになります。
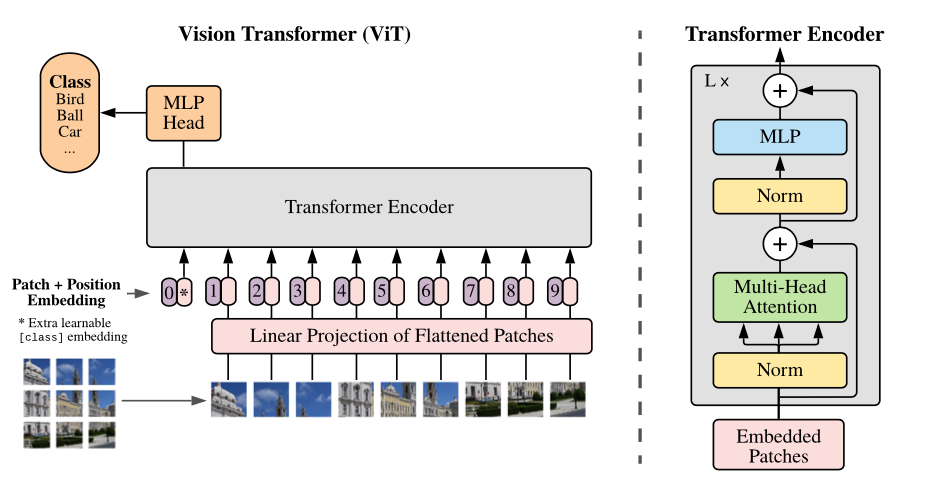
↑図はViTアーキテクチャを示したブロック図です。図の左下で画像をパッチに分割しています。それぞれのパッチへPosition(位置情報)を付加し、Transformer Encoderでベクトル化 → 識別器(MLP)へ入れることで分類していきます。超簡単な説明ですが、これがViTのアーキテクチャ全貌になります。
CNNでは全結合層を介すことで画像の位置情報が失われてしまうといわれています。ViTは位置情報を保持することで画像の離れた場所で特徴がある場合も良く認識することができると言われています。
さらに詳しい説明は論文か、もしくはこのサイトに詳しくまとまっているので併せてご覧ください。
学習環境
ここから学習実装の説明をしていきます。
学習環境
ローカルGPU環境で実装していきます。ViTの学習にはGPUがないとキツイです。CPU環境の方はGoogle Colabを利用することをお勧めします。
- OS : Windows 11
- CPU : AMD Ryzen7 5800
- メモリ : 16GB
- GPU : GeForce RTX3070 8GB
CUDA関連
- CUDA : 11.4
- cuDNN : 8.2
CUDA, cuDNNはご自身の環境に合ったモノを導入してください。このサイトに導入方法が細かく掲載されていますので確認してみてください。
Python
- Python : 3.8.12
ライブラリ
- PyTorch : 1.8.1 + cu111
- scikit-learn : 1.0.2
- timm : 0.5.4
- tqdm : 4.62.3
- vit-pytorch : 0.26.7
この辺りをpip installしてください。あとは必要に応じて👍
コード
コードはViTをPyTorchで実装したvit-pytorchを使わせてもらいました。

コードのダウンロードもしくはgit cloneして作業フォルダをつくってください。分からない方はここを参考にしてください。
学習データセットの準備
作業フォルダ中のexamplesに入っている「cats_and_dogs.ipynb」をベースにViTを実装していきます。学習データセットはKaggle※からtrain.zip, test.zipをダウンロードしてください。※Kaggleのデータセットをダウンロードするためにはアカウント登録(無料)が必要です。
↓のフォルダへ保存してください。
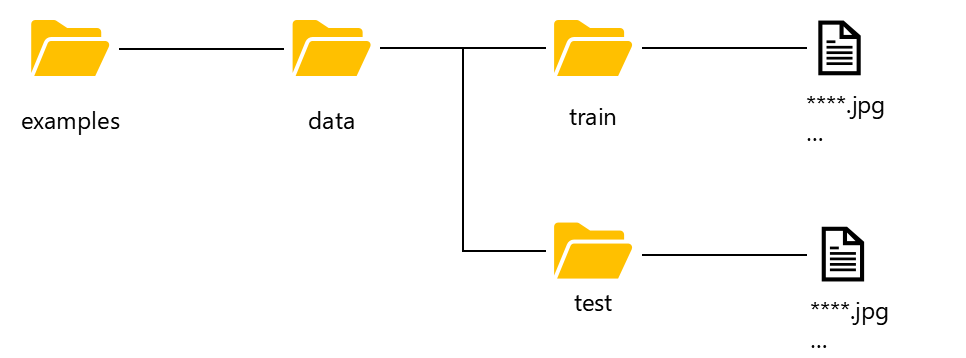
- train : 25,000
- test : 12,500
ViTの実装
今回はvit-pytorchのexamplesをベースに実装を進めていきます。
実装はAnacondaのJupyterNotebookを想定して記載します。必要あればインストールしてください。Anacondaって!?という方はここを参考にしてください。
コードを開く
作業フォルダのexamples→cats_and_dogs.ipynbをJupyterNotebookで開いてください。
Import Libraries ライブラリのインポート
from __future__ import print_function
import glob
from itertools import chain
import os
import random
import zipfile
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from linformer import Linformer
from PIL import Image
from sklearn.model_selection import train_test_split
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
from tqdm.notebook import tqdm
from vit_pytorch.efficient import ViT
import seaborn as sns #←これを追加
import timm #←これを追加seabornとtimmを追加してください。ここでエラーがでた場合はpip install ***で必要なライブラリをインストールしてください。
# Training settings
batch_size = 64
epochs = 20
lr = 3e-5
gamma = 0.7
seed = 42def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
seed_everything(seed)学習の設定、シード関連の設定をしていきます。ここはデフォルトのままでいきます。
device = 'cuda'GPUを使っていくので’cuda’を指定します。
Load Data 学習データの設定
#os.makedirs('data', exist_ok=True) これは飛ばしてもOKです。
train_dir = 'data/train'
test_dir = 'data/test'↓のコードはエラーになるので飛ばしてください。
#このブロックは飛ばしてください!
with zipfile.ZipFile('train.zip') as train_zip:
train_zip.extractall('data')
with zipfile.ZipFile('test.zip') as test_zip:
test_zip.extractall('data')↓ここからは実行するだけです。
train_list = glob.glob(os.path.join(train_dir,'*.jpg'))
test_list = glob.glob(os.path.join(test_dir, '*.jpg'))print(f"Train Data: {len(train_list)}")
print(f"Test Data: {len(test_list)}")Train Data: 25000 Test Data: 12500
↓ここでファイル名(Dog, Cat)を取得しリスト化します。このリストが分類ラベルになります。実行するだけでOKです。
labels = [path.split('/')[-1].split('.')[0] for path in train_list]Random Plots
学習データセットのなかからランダムで画像が出力されます。データをうまく読み込めているか確認するために実行しておきましょう。
random_idx = np.random.randint(1, len(train_list), size=9)
fig, axes = plt.subplots(3, 3, figsize=(16, 12))
for idx, ax in enumerate(axes.ravel()):
img = Image.open(train_list[idx])
ax.set_title(labels[idx])
ax.imshow(img)Split
train data と validation data に学習データを分けます。
train_list, valid_list = train_test_split(train_list,
test_size=0.2,
stratify=labels,
random_state=seed)print(f"Train Data: {len(train_list)}")
print(f"Validation Data: {len(valid_list)}")
print(f"Test Data: {len(test_list)}")Train Data: 20000 Validation Data: 5000 Test Data: 12500
↑のようにデータが分割できていればOKです。
Image Augumentation
Data Augmentationを定義していきます。ここもデフォルトでtransforms.RandomHorizontalFlip(左右反転)だけを実施していきます。サイズを合わせるためtransforms.CenterCropも実行します。
train_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]
)
val_transforms = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
]
)
test_transforms = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
]
)Load Datasets
PyTorchは学習データの画像、ラベルの読み込みに対しDatasetで定義し、DataLoaderでData AugmentationだったりBatch sizeにデータを分けたりします。
↓のブロックの一か所(”train\dog”)だけ書換えてください。あとは実行していくだけです。
class CatsDogsDataset(Dataset):
def __init__(self, file_list, transform=None):
self.file_list = file_list
self.transform = transform
def __len__(self):
self.filelength = len(self.file_list)
return self.filelength
def __getitem__(self, idx):
img_path = self.file_list[idx]
img = Image.open(img_path)
img_transformed = self.transform(img)
label = img_path.split("/")[-1].split(".")[0]
label = 1 if label == "train\dog" else 0 #ここを書換えてください
return img_transformed, label
train_data = CatsDogsDataset(train_list, transform=train_transforms)
valid_data = CatsDogsDataset(valid_list, transform=test_transforms)
test_data = CatsDogsDataset(test_list, transform=test_transforms)train_loader = DataLoader(dataset = train_data, batch_size=batch_size, shuffle=True )
valid_loader = DataLoader(dataset = valid_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset = test_data, batch_size=batch_size, shuffle=True)print(len(train_data), len(train_loader))20000 313
print(len(valid_data), len(valid_loader))5000 79
Efficient Attention
Efficient Attentionは文字通りAttentionを効率化させる技術です。Attentionでの計算コストを下げる効果があります。いろいろなアルゴリズムが提案されていますがexamplesどおりLinformer↓を使っていきます。ハイパーパラメータはデフォルトのままいきます。
efficient_transformer = Linformer(
dim=128,
seq_len=49+1, # 7x7 patches + 1 cls-token
depth=12,
heads=8,
k=64
)ViTのモデルを呼び出します。ハイパーパラメータをここで設定できるのですが、デフォルトのままいきます。
model = ViT(
dim=128,
image_size=224,
patch_size=32,
num_classes=2,
transformer=efficient_transformer,
channels=3,
).to(device)ここでのパラメータを簡単に説明すると↓の感じです。
- dim : ベクトル変換後の次元。(大きいと情報量は多いですが、計算が重くなります)
- image_size : 画像のサイズ。長方形の場合、長い辺のサイズ。
- patch_size : 画像を切り出すパッチの数。Transformerの特徴的な変数。
- num_classes : 分類クラスの数。今回はDog, Catなので2
- transdormer : efficient attentionをここで指定。
- channels : チャンネル数。RGBの場合3。
ここでpatch_sizeを変更した場合、上記Linformerのseq_lenを変更するようにしてください。seq_lenはpatch_size × patch_size +1です。
Training
ロスの設定です。OptimizerはデフォルトでAdamですが変更する場合はここで↓
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)学習していきます。今回は学習曲線を出力したいので、ログを取得するコードを追記しています。
##ここを追記↓##
train_acc_list = []
val_acc_list = []
train_loss_list = []
val_loss_list = []
##############
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
##ここを追記↓##
train_acc_list.append(epoch_accuracy)
val_acc_list.append(epoch_val_accuracy)
train_loss_list.append(epoch_loss)
val_loss_list.append(epoch_val_loss)
##############
こんな感じで学習が進んでいくと思います。
学習結果の可視化
ここからはexamplesにありませんのでコードを追記してください。
#出力したテンソルのデバイスをCPUへ切り替える
device2 = torch.device('cpu')
train_acc = []
train_loss = []
val_acc = []
val_loss = []
for i in range(epochs):
train_acc2 = train_acc_list[i].to(device2)
train_acc3 = train_acc2.clone().numpy()
train_acc.append(train_acc3)
train_loss2 = train_loss_list[i].to(device2)
train_loss3 = train_loss2.clone().detach().numpy()
train_loss.append(train_loss3)
val_acc2 = val_acc_list[i].to(device2)
val_acc3 = val_acc2.clone().numpy()
val_acc.append(val_acc3)
val_loss2 = val_loss_list[i].to(device2)
val_loss3 = val_loss2.clone().numpy()
val_loss.append(val_loss3)
#取得したデータをグラフ化する
sns.set()
num_epochs = epochs
fig = plt.subplots(figsize=(12, 4), dpi=80)
ax1 = plt.subplot(1,2,1)
ax1.plot(range(num_epochs), train_acc, c='b', label='train acc')
ax1.plot(range(num_epochs), val_acc, c='r', label='val acc')
ax1.set_xlabel('epoch', fontsize='12')
ax1.set_ylabel('accuracy', fontsize='12')
ax1.set_title('training and val acc', fontsize='14')
ax1.legend(fontsize='12')
ax2 = plt.subplot(1,2,2)
ax2.plot(range(num_epochs), train_loss, c='b', label='train loss')
ax2.plot(range(num_epochs), val_loss, c='r', label='val loss')
ax2.set_xlabel('epoch', fontsize='12')
ax2.set_ylabel('loss', fontsize='12')
ax2.set_title('training and val loss', fontsize='14')
ax2.legend(fontsize='12')
plt.show()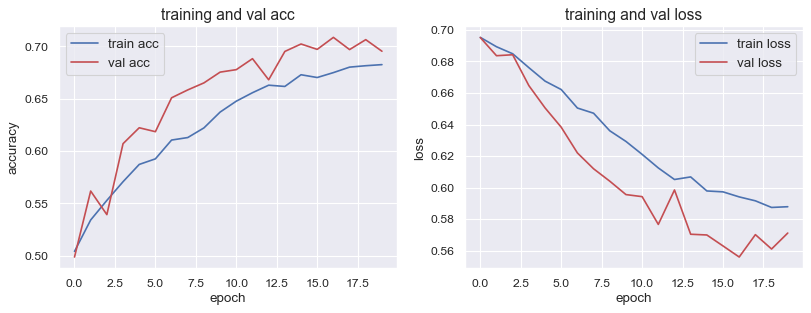
こんな感じで学習曲線が出力できました。
- Validation accuracy : 0.692
- Validation loss : 0.572
といった結果でした。まずまずですが、そこまで高精度!といった感じではありません。
冒頭でも説明しましたが、ViTは大量のデータで学習したpre-trained modelをファインチューニングすることで真価を発揮します。ということで、ファインチューニングしてみようと思います。
ViTをファインチューニングして真価を発揮させる
timmを使ってViTのpre-trained modelをダウンロードし、さらにファインチューニング学習を実行していきます。
timmはPyTorch Image Modelsライブラリで、いろいろなモデルとpre-trainedデータがそろっているライブラリです。数百種類のモデルを備えているので「最強の画像認識ライブラリ」とも言われています。これを利用していきます。
何のこっちゃ?と思う方もいるかと思いますが、コードを実行するとできてしまうので大丈夫です。↑で書いたコードのEfficient Attentionの部分をコメントアウトし、↓のコードへ置き換えてください。
#efficient_transformer , modelの部分はコメントアウト
from pprint import pprint
model_names = timm.list_models(pretrained=True)
pprint(model_names)['adv_inception_v3', 'bat_resnext26ts', 'beit_base_patch16_224', 'beit_base_patch16_224_in22k', 'beit_base_patch16_384', 'beit_large_patch16_224', 'beit_large_patch16_224_in22k', 'beit_large_patch16_384', ・・・・・・
たくさんモデルが出てきますが、今回はこの中から「vit_small_patch16_224」を選びました。これは画像サイズ:224pixel、Patch_size : 16の比較的小さいpre-trained modelになります。もっと大きなモデルもありますが、私の環境ではOOMでしたのでsmallを選択しました。
↓のコードを実行しモデルを定義してください。初回は重みデータをダウンロードするので時間がかかります。
model = timm.create_model('vit_small_patch16_224', pretrained=True, num_classes=2)
model.to("cuda:0")モデルを定義したら、Trainingへ進み実行していくだけでOKです。
↓のように学習が進むと思います。1epoch目で既におかしな精度が出ています。

最後に学習曲線をプロットすると↓の感じです。

- Validation accuracy : 0.996
- Validation loss : 0.0118
とんでもない高精度モデルが完成しました!正直これが出たときに驚きました。これは面白いので、いろいろなデータで試してみようと思います。
CNNで精度に困っている方、一度試してみてはいかがでしょうか。
今日も良いディープラーニングライフを👍
参考資料
ViT, Transformer
- https://qiita.com/omiita/items/0049ade809c4817670d7
- https://www.youtube.com/watch?v=FFoLqib6u-0&t=2s
timm
- https://github.com/rwightman/pytorch-image-models
- https://rwightman.github.io/pytorch-image-models/
- https://towardsdatascience.com/getting-started-with-pytorch-image-models-timm-a-practitioners-guide-4e77b4bf9055
コメント
いつも記事楽しみにしています。特に実装編は分かりやすくて参考になります。
この記事に対しての質問ですが、train_lossに対してval_lossが低いのはモデルとして良いんでしょうか?
一般的にval_lossの方が学習に使われていないデータのため高くなると認識していました。自分が画像分類する際も同じような現象が起きたり、起こらなかったりするのでFarmLさんの意見を伺いたいです。
しめ鯖さん
コメントありがとうございます。
val_lossが低くなる現象はたまにありますね。原因としてはいくつか考えられると思います。
・データ数が十分ではなく、trainとvalidationデータセットに偏りが生じている
・trainデータはDataAugmentationをしているの精度がブレている
などが考えられると思います。
モデルとして良いか悪いかと言えば、train_lossが順調に減っているので悪くはないと思います。
ただし、過学習が見えずらいので、実運用前にデータ数を増やす対応は必要かと思います。
こんなところでしょうか!?
返信ありがとうございます。確かにtrainデータにDataAugmentationをしていることが一番影響してそうですね。特に今回のようにAccuracyが高くなるようなタスクの場合はtrain_lossが低くなることも多いのかもしれません。自分としては学習に使わない評価データで判断したいと思います。