

人間は目で見たモノが近くにありそうか、遠くにありそうか把握することができます。これは両目から得られた情報を脳で処理することで可能にしているようです。一方、カメラなど単眼で撮影した画像の中で、モノまでの距離を推定することは難しいことです。
今回はMiDaSという深度推定AIモデルを使って画像中のモノの距離を表現してみます。MiDaSはさまざまなデータセットで学習されているので、汎用性が高いモデルです。

※注意!音出ます
深度推定モデルMiDaSについて
MiDaSのモデルについて簡単に説明してみます。
論文では明記されていないようですが、MiDaSモデルはおそらくセマンティックセグメンテーションモデル※と思われます。
データセットを見ると↓のようなオリジナル写真/深度マップの組み合わせになっています。

オリジナル写真をインプット、深度マップをアウトプットとして学習しているモノと考えられます。EncoderはResNet101※を用いているようですが、Decorderについては論文に記載がありませんでした。
複数のデータセットをつかって学習していると冒頭に述べましたが、ここで大変苦労しているみたいです。それぞれのデータセットで深度スケールに互換性が無いからです。LOSSを工夫して乗り越えています。
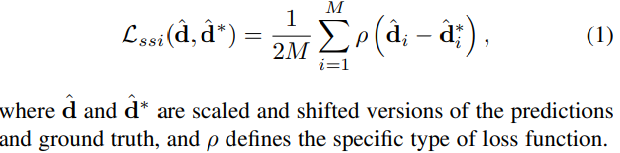
https://arxiv.org/pdf/1907.01341v3.pdf
各データセットの深度値dをそのまま使うのではなく、真値の推定d^を定義してLOSSをつくっています。
実際つかう分にそこまで気にしなくても大丈夫です。詳しく知りたい方は論文を読んでみてください。LOSSを工夫するとよい学習できる面白い事例だと思います。
MiDaSの準備
実行環境
ローカルGPU環境で実装していきます。GPU環境で動作確認していますが、推論だけなのでCPUでも動くと思います。
- OS : Windows 10
- CPU : AMD Ryzen7 5800
- メモリ : 16GB
- GPU : GeForce RTX3070 8GB
CUDA関連
- CUDA : 11.4
- cuDNN : 8.2
Python
- Python 3.8.8
ライブラリ
- PyTorch 1.8.0 + cu111
- OpenCV 4.5.2.52
- timm 0.5.4
コード
コードは↓のモノをつかわせてもらいました。
コードのダウンロードもしくはgit cloneして作業フォルダをつくってください。
学習済み重みのダウンロード
MiDaS Githubの中段辺りに「Setup」という見出しがあると思います。そこに重みのリンクが張ってあります。
精度と処理速度が背反しますので何を優先するか、お好みの重みをダウンロードしてください。全部ダウンロードしても大丈夫です。
ダウンロードした重みデータは↓のフォルダへ保存してください。
MiDaS
-> weights
-> dpt_large-midas-2f21e586.pt
-> dpt_hybrid-midas-501f0c75.pt
-> midas_v21_small-70d6b9c8.pt
-> midas_v21-f6b98070.pt
準備は以上です。
MiDaSをつかってみる
深度を推定したい画像データをinputへ格納してください。高解像度の画像でも推論できますが、384x384pixelで学習しているのでそのくらいの大きさの画像が良さそうです。
↓の画像でやってみようと思います。画像をMiDaS/inputフォルダへ入れてください。

AnacondaPromptなどで↓のコードを実行してください。
cd desktop/MiDaS
python run.py --model_type dpt_large --input_path ./input --output_path ./output引数を説明します。
--model #学習済み重みの選択
dpt_large
dpt_hybrid
midas_v21_small
midas_v21
--input #インプットデータのpath。フォルダ選択も可
--output #アウトプットデータのpath。フォルダ選択も可
実行するとアウトプットフォルダに結果データが保存されます。

深度マップが生成されたと思います。木はよく推定されているみたいです。一方で左端のベンチはうまく推定できていないでしょうか。細かく検証したわけではありませんが、得意不得意はありそうです。
ちなみにデフォルトの設定だと深度推定マップはグレースケールで表示されます。味気なかったので↓をいじってカラーマップを変えています。参考にやり方載せておきます。
#run.py 139行目
utils.write_depth(filename, prediction, bits=1) #bits=2 -> 1
#utils.py 186行目をコメントアウト→追記
#cv2.imwrite(path + ".png", out.astype("uint8"))
out = out.astype(np.uint8)
out = cv2.applyColorMap(out, cv2.COLORMAP_MAGMA)
cv2.imwrite(path + ".png", out)
書き換えて実行するとカラーマップ変わると思います。
いろいろやってみる

車、木、人などImageNetにありそうなモノは間違いなく認識していそうです。

野菜もいけそうですね👍
野菜の収穫ロボットなどはこういう技術をつかっている?のかもしれませんね。FarmLでは大掛かりなロボットとかではなく、人をサポートするAIを考えているので、もっと違った活用方法はないか・・・考えてみます。
深度推定はMiDaSによって大分熟成されてきた技術かと思います。そこまで難しいことはないので是非試してみてください。
※記事紹介
FarmLブログでは過去にセマンティックセグメンテーション、ResNetの記事を書いています。この辺りを知りたい方は↓も併せてご覧ください。





参考書籍のご紹介
FarmLブログでは「AIをやってみたい! 」「全然わからないけど面白そう!」みたいな人を応援しています。
まずは事例付きの書籍などを一通りやると感覚つかめるので試してみたください👍
↓おすすめな関連書籍のご紹介。
コメント