

画像データをディープラーニングすることで様々なことができるモデルをつくることができます。過去の記事にてCNNモデルでは画像認識で花の分類をしました。YOLOモデルでは物体検出でスナックエンドウを検出しました。ここでは画像データのディープラーニングで物体の境界線を描くセグメンテーションを実装していこうと思います。今回はセグメンテーションとは?についての解説編です。
- 書籍が難しすぎて挫折した
- これからデータサイエンティストを目指したい
- 画像データのディープラーニングに興味がある
ニューラルネットワークの基本を理解されている方を対象としています。基本を知りたい方は過去の記事も併せてご覧ください↓

セグメンテーションタスクについて
セグメンテーションは画像のpixelごとに識別を実施することで、Image to Image translation「画像を入力し、画像を出力する」タスクです。
CNN(畳み込みニューラルネットワーク)とセグメンテーションタスクは考え方が似ているのでの違いを比較しながら進めていきます。
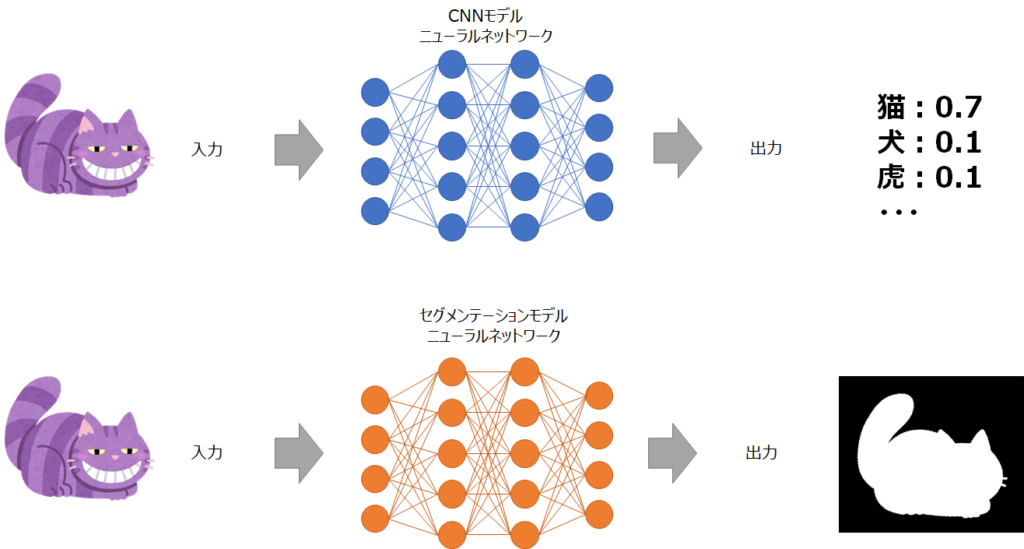
まずCNNは画像データを入力後、ニューラルネットワークを介し「猫」「犬」「虎」などの確率値を出力するモデルでした。一方でセグメンテーションモデルは入力する画像データはCNNと同様ですが、出力として↑図のような画像の境界が出力されます。これは画像のピクセルごとに分類結果を出力したモノです。つまり背景なのか?猫なのか?を1ピクセルごとに分類した結果を出力しているということです。
セグメンテーションにもいくつか種類があります。
- セマンティックセグメンテーション
画像全体についてセグメンテーションをするタスクになります。人、車、自転車などのクラスに分類するため、↓図の真ん中のように「人」をピクセル単位で分けることができます。
- インスタンスセグメンテーション
物体検出をした領域に対しセグメンテーションをするタスクになります。物体検出により五人の人を検出してからセグメンテーションをするため、↓の図の右のように一人一人をピクセル単位で分けることができます。

今回はセマンティックセグメンテーションを使っていこうと思います。家庭菜園としてはお馴染み?スナックエンドウで挑戦していこうと思います。↓の感じ。タイトルに家庭菜園と書きながら、家庭菜園ネタが少なくてすみません。。。

セマンティックセグメンテーションの仕組み
ここでもCNNと比較しながら説明していきます。まず、CNNではConvolution(畳み込み)層でデータの特徴量を抽出しながら、画像サイズを小さくしていき、最終的に分類するクラスの確率値を出力していました。つまり画像を特徴付けることが目的なので、画像サイズを小さくしたままで問題ないのです。
一方で、セマンティックセグメンテーションモデルはImage to Image translationタスクなので、入力画像と同じサイズの画像データを出力する必要があります。これを実現するためには特徴量を集約するために、いったん小さくしたデータを復元するupsamplingをする必要があります。セマンティックセグメンテーションモデルとして有名なU-Netモデルを使い説明していきます。
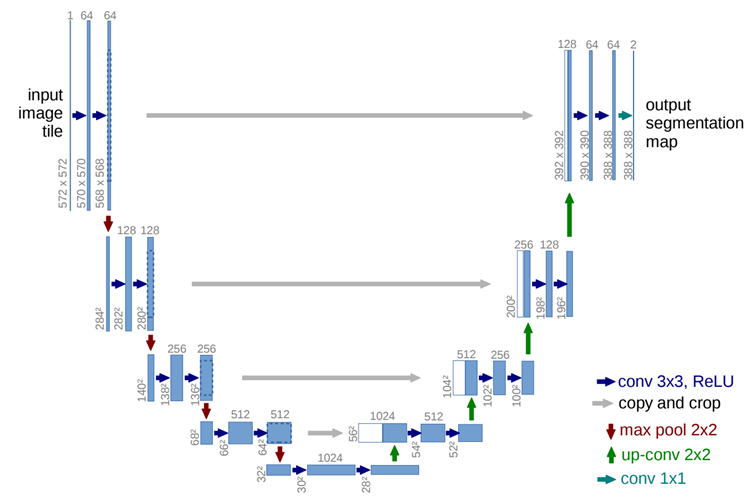
U-Netの名前の由来は↑のようなUの字のモデルから来ています。なんだか難しい感じがしますが、半分は既に理解している内容となっています。↑の図に少し説明を書き加えます。
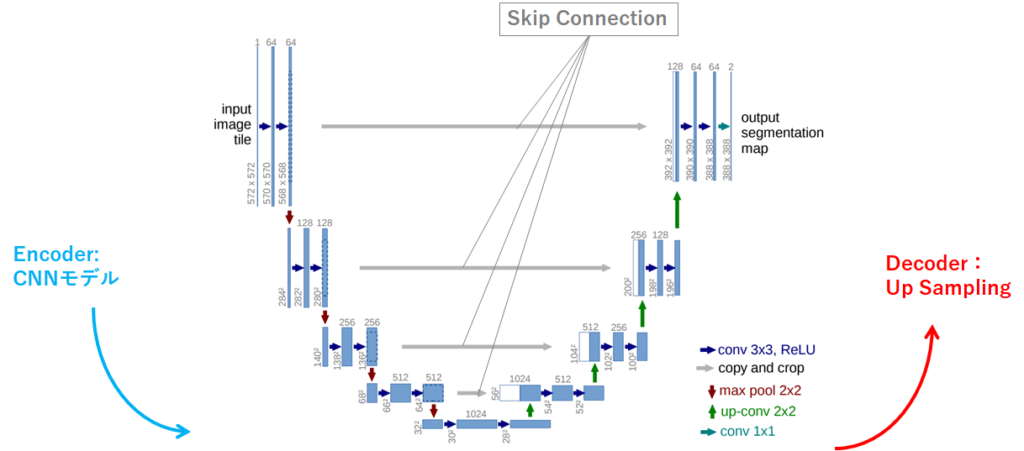
U-Netモデルの左半分はEncorderと呼ばれ、CNNで特徴量を抽出していく工程になります。一方で、右半分はDecorderと呼ばれ、抽出した特徴量を基に境界線の画像へデータを増やしていきます。
Decorder工程のup-convで畳み込みと逆処理を実施し、データを復元していくのですが、この時に問題が発生します。そもそも、特徴量を抽出するEncorder工程のmax poolで削減した情報を復活させるわけで、どこのpixelをプーリングしたのか?という情報が無ければ、その辺りの復元が曖昧になりますよね。その解決策としてU-NetではSkip Connectionという技術が用いられています。プーリング前の情報をup-conv前に渡すことで、データの復元を助けようという動きのことです。過去に説明したResNetのResidual Blockと似たような発想ですが、Residual Blockはニューラルネットワークの勾配消失などの問題に対応しているのに対し、Skip Connectionはプーリング前の情報を与えて補間してあげるようなイメージになります。詳細は論文をご確認いただけると良いかと思います。
今回はU-Netを使ってセマンティックセグメンテーションモデルをつくっていこうと思います。
まとめ
- セグメンテーションタスクは物体の境界線を描くモノで画像のpixelごとに識別するモデル
- セグメンテーションにはセマンティックセグメンテーションと、インスタンスセグメンテーションの2種類がある。
- セマンティックセグメンテーションはクラスごとに境界線を描くのに対し、インスタンスセグメンテーションは物体検出と併せることで同クラスでもさらに一つ一つのモノで分類することができる。
- U-NetはEncorder-Decorder構造の代表的なセマンティックセグメンテーションモデルであり、特徴としてSkip Connection技術により、Decorderで画像を復元するのを助ける構造となっている。
コメント