

私がポイントとして考える、AIの基礎をできるだけ簡単な形でお伝えします。書籍等で勉強する前にご一読いただけると、理解を深めることができると思います!
ヒストグラムとは、AI・機械学習に興味がある方は聞いたことあると思いますが、ヒストグラムとは私が思うに最もよく使うグラフの1つです。というのもヒストグラムのは他のグラフと違い抽象的な見方をするという面白い特徴があります。例えば訓練を受けていない人が見るとただのグラフでも、ヒストグラム熟練者がみると問題を発見可能性がある、という便利ツールです。では、行ってみましょう!!
- ヒストグラムはどんなグラフ?
- ヒストグラムの書き方
- ヒストグラムからどんなことが分かるか
- pythonコード
ヒストグラムはどんなグラフ?
まずはグラフを見てみましょう!
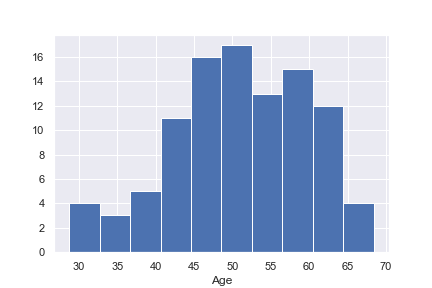
こんな感じのグラフです。このグラフの場合は横軸が年齢になっており、縦軸は人数となります。とある年齢の区間に何人いますか?ということを示したグラフになります。
このグラフから50代を中心に、40~65歳あたりまでが集まる謎の集団ということが読み取れますね。このような感じで、そこに存在する集団の特長(分布)を捉えることができるのがヒストグラムです。
ヒストグラムの書き方
グラフを描くためにエクセル、pythonなどを使えば簡単に描写することはできますが、ヒストグラムは実は描き方で解釈が大きく異なってしまうので説明させてください。まずはヒストグラムの描き方の手順です。
- データを収集する。最低でもデータ数n=30以上はあった方が良い
- データの最大値max(x)、最小値min(x)を求める
- 区間(横軸)の数hを決める。区間の数は以下の式に従い仮に決めておく。$$h≒\sqrt{n}$$
- 区間の幅cを決める。これは整数倍に値を丸めた方が分かりやすい。$$c=\frac{max(x)-min(x)}{\sqrt{n}}$$
- 区間に収まるデータの個数を度数(縦軸)としてグラフを描く。
描き方の手順としてはこんな感じですが、ここで区間の数というのが重要となってきます。pythonのmatplotlibで作図すると引数binsで指定できるが、デフォルトで10になっている。これを変化させたときに何が起こるか見てみます。
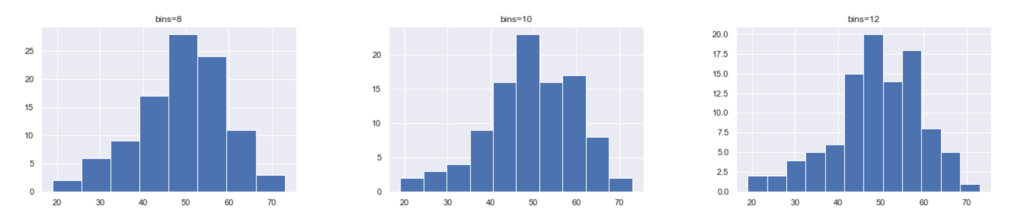
上図はデータ数n=100に対し、区間数(bins)を8,10,12で設定して作成したグラフです。上記の手順で作図するとbins=10となるため真ん中のグラフになり、50付近と60付近にピークがあることがなんとなくわかります。一方でbins=8とすると左のグラフとなり、60付近のピークが見えなくなります。また、bins=12にすると60付近のピークがはっきり分かるようになります。
ピークを見失うということは重要な要素を見逃すということなので、避けなければなりません。従ってヒストグラムを描くときにbinsの数値を変化させデータの特長を見るということを意識的にやってみてください!私の経験ですが、データ数の平方根に+2(今回の場合bins=12)を見ておくことをおすすめします。$$h≒\sqrt{n}+2$$
ヒストグラムの見方
ヒストグラムをどう見るか、ポイントは3つです。
- 山の形
- 平均値、データの偏り
- 外れ値
理想的なヒストグラムは正規分布※と同じ形状をしています。※見ている確率分布によって理想的な形状は異なりますが、一般的によくわからないデータを見るときは正規分布と比較します。
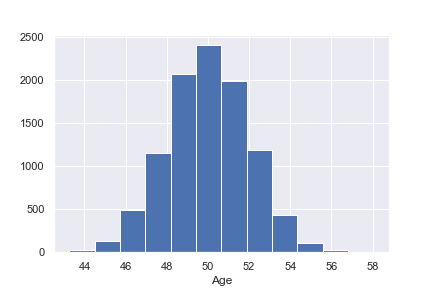
山の形:一山形、平均値:山の中心・データの偏り:左右対称、外れ値:なし。このような状態であれば、分布が管理されている状態といえるのでイレギュラーが起こりにくく、機械学習へ投入した際の予測精度は高くなります。
一方で、こんなときはデータの前処理(層別)を実施した方が良いので注意してください。
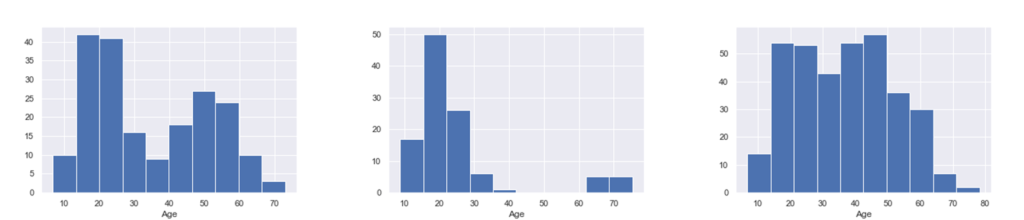
上記グラフは左から二山形、離れ小島形、高原形と言われる分布形状でどれにも共通して言えることは層別が必要ということです。層別とは、例えば左のグラフだと20代中心の山と、50代中心の山の二山に見えるので、山を分けて(データを分けて)別々に問題を考えることです。このようなデータを特徴別に分けること=前処理は機械学習の精度を上げるためには重要な仕事となります。
分布の特長がよく分からないときは、とにかく層別してみましょう。
まとめ
- ヒストグラムは集団の特長(分布)を捉えるためのグラフ
- ヒストグラムは他のグラフとは違い分布形状を抽象的なイメージで理解する
- ヒストグラムを描くときにbinsの数値を変化させデータの特長を見る
- 理想的なヒストグラムは正規分布と同じ形状
- 分布が正規分布していないときは、とにかく層別してみる
pythonコード
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set()
a = np.random.normal(loc = 50, scale = 10, size = 100) #loc:平均、scale:標準偏差、size:データ数を指定
df_a = pd.Series(a, name="Age")
plt.hist(df_a, bins=10) #bins=数値を適当にいじってデータの特長を見る
plt.xlabel("Age", fontsize=12)
コメント