

「畳み込み」カーネル値を変えることで様々な角度から画像の特徴を捉えることができるのを前の記事で紹介しました。ここでは「畳み込み」で得られた特徴量をニューラルネットワーク(ディープラーニング)で学習していく際に、どのような工夫が必要か?どんな学習モデルをつくればよいか?代表的なモデリングをご紹介します。
畳み込みについて説明が必要な場合は↓を参照してください。

ディープラーニング(多層パーセプトロン)については↓に詳細を説明しているので、参考にしてください。

- AI・機械学習を勉強したいけど、何からやればよいか分からない
- 書籍が難しすぎて挫折した
- これからデータサイエンティストを目指したい
- 画像認識をやってみたい
畳み込みニューラルネットワーク(CNN)のモデルについて
CNNは多層パーセプトロンのモデルなので以前説明したように活性化関数が必要となる。それ以外にBatch Normalization、Max pooling、Affine(全結合層)といったテクニックを使っていくのが効率よく学習を進める方法の”お手本”となっています。もちろん全てこれをやってればOKというわけではありません。試行錯誤する前に、とりあえずやっておくと意外と良い結果がでるケースが多いといった感じです。
↓にCNNモデルのイメージを図示します。これは、Neural Network Console(sony)※でモデル設計をしたイメージです。非常にわかりやすいのでこれを使います。※Neural Network Consoleはコーディング無しでディープラーニングをできるツールです。
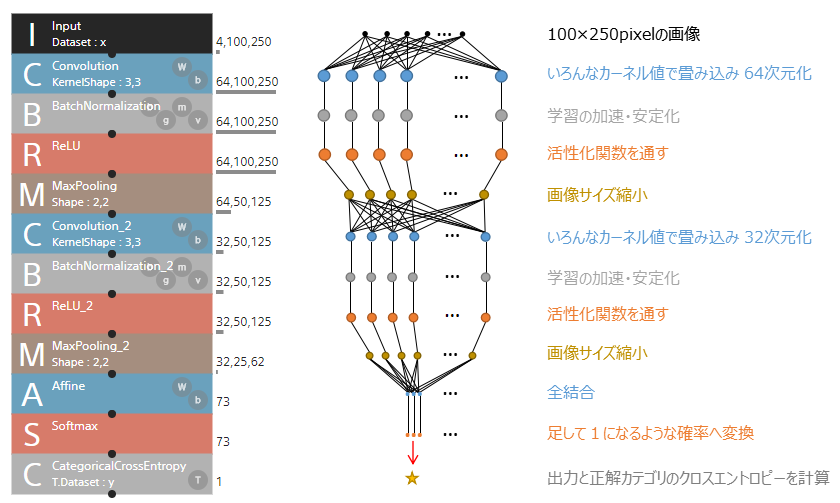
左のボックスを積み重ねた図がNeural Network Consoleで組み立てたモデルの模式図で、右に中身を解説しています。丸がニューロンで直線がネットワークの繋がりと考えてください。
- 水色のボックスがニューラルネットワークの中間層なので、このモデルは3層のニューラルネットワークです。
- 中間層のあとにBatchNormalization、活性化関数ReLUを通してモデルの学習速度UP、表現力を向上させています。
- 活性化関数のあとにMaxPoolingを実施し、特徴を捉えていない部分を削除することで計算量を減らします。
- 上記の流れをもう一度繰り返したあとに全結合層を通します。全結合層ではカーネルを用いらず全てのデータに対し重みを算出していきます。
- 次にSoftmaxは活性化関数の一種で全データを足して1になるような確率変換を実施します。
- 最後にCategoricalCrossEntropyは出力と正解の差を計算します。これを最小化するように誤差逆伝播でニューラルネットワークを最適化していきます。
一連の流れは以上のようになっています。畳み込み(Convolution)につては前の記事で説明していますので、他のステップについて詳細を説明していきます。
Batch Normalization とは
ディープラーニングにおいて畳み込み層を重ねてモデルを深くすることで精度を上げていきます。近年では100層を超えるような巨大なモデルを使うのが普通となっています。層が深いモデルで問題になってくるのが内部共変量シフトです。
内部共変量シフトを簡単に説明すると、1回目の学習中に1層目のニューロンから2層目へデータを受け渡す際、データがある分布Aに従っているとします。1回目の学習が終わると誤差逆伝播で重みのみが更新され、2回目の学習では1層目の出力データの分布がBへ変化することがあります。これが内部共変量シフトです。ここで2層目は分布Aで重みを更新しているため、新たに重みを最適化する必要があり効率が悪化します。
そこで、Batch Normalizationを利用します。Batch Normalizationの中で何をやっているか?ですが、入力する画像のmini batch(一回に処理する複数の画像)間で正規化する(中間層の出力が平均0、分散1となるように変換する)ことです。
Batch Normalizationを使うメリット
- 学習の安定化に伴う速度アップ
- Dropout(局所的に重みを忘れる)を使わなくても良くなる
- 重みの初期値への依存が小さくなる
Max pooling とは
畳み込みを重ねていくことで、データ容量が加速度的に増加していきデータが扱いずらくなっていくので、影響の小さい情報を削除し、ダウンサンプリングするのがpoolin層です。poolingすることで特徴量を際立たせたり、ばらつきに強くなる効果があります。
Max poolingはpooling層で実施するテクニックの一つです。
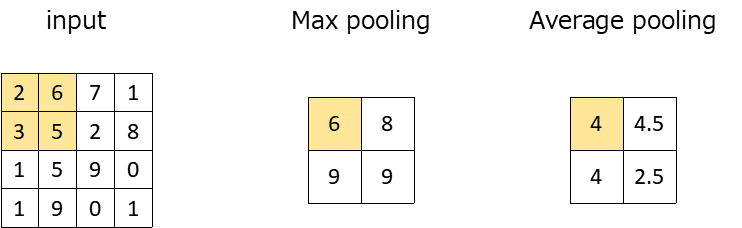
Max poolingは設定範囲内(ここでは2×2)で最大値を取る処理です。ほかに平均を取るAverage poolingがあります。設定範囲は任意で決めることができます。
Max poolingを使うメリット
- 計算コストを下げることができる
- ばらつきに強くなる(頑健性)
- 過学習を抑制する
- 特徴を際立たせることで検出し易くする
全結合層 Affine について
全結合層ではカーネルを使った畳み込みを実施せず、全ての入力ニューロンの値に重みをかけてそれぞれを加えることでデータを出力していく。↓の例でいくと、32x25x62=49600のニューロンにそれぞれ異なる重みをかけて73のデータをアウトプットしていくことになります。全部を結合するので全結合と言われるんですね。
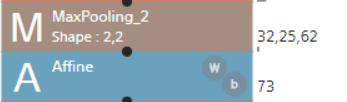
Convolution(畳み込み層)はカーネルで重みが共有されているため、例えば3×3のカーネルであれば9パラメータ(重み)をもつのですが、一方でAffineはそれぞれのアウトプット別に重みをもっているので49600×73=3620800パラメータをもつという違いがあります。
畳み込み層では画像の特徴を抽出する。全結合層はそのあとのクラス分類へ繋ぐというモデル構成になっているためパラメータに大きな差が生じます。
活性化関数とロス関数(Softmax, Categorical Cross Entropy)
モデルの最後に活性化関数とロス関数を設定します。ここでは解きたい問題によって、それに合致するものを選ぶ必要があります。
| 2値分類問題(○×判断) | クラス分類問題(犬、猫、、、) | 回帰問題(数値予測) | |
| 活性化関数 | Sigmoid | Softmax | なし |
| ロス関数 | Binary Cross Entropy | Categorical Cross Entropy | Squared Error |
今回はクラス分類問題と仮定しておりSoftmax、Categorical Cross Entropyをモデルの最後に設定しています。Softmaxでは全データを足して1になるような確率変換を実施します。Categorical Cross Entropyでは出力と正解の差を計算しています。
これらは絶対的なモノではなく、例えばロス関数は問題によって自分で設定することもあります。この辺りは慣れていく必要があるのですが、ひとまず↑の表で覚えておくと様々な問題に対応できると思います。
まとめ
- 畳み込みニューラルネットワークは、畳み込んだデータをBatch Normalization, Max pooling, Affine(全結合層)といったテクニックで学習していく
- Batch Normalizationは学習を安定化させ速度UPする効果がある
- Max poolingは計算コストを下げる、ばらつきに強くなる等の効果がある
- 全結合層は全部のニューロンとアウトプットを結合する層で、そのあとのクラス分類へ繋ぐ役割がある
- 最後の活性化関数とロス関数は解きたい問題によって合致するものを選ぶ必要がある
コメント