

独自のデータを用いたYOLOv5の物体検出に挑戦していきます👍
前の記事でYOLOv3を使った物体検出を実行したのが面白かったので、YOLOv5でも物体検出やってみました。Windows10環境です。
今回は独自データをつかってみる「基礎編」ですが、様々な応用的な技術にも挑戦しています。よろしければ併せてご覧ください。
前の記事(YOLOv3)についての詳細は↓を見てみてください。


YOLOv5とは、物体検出をするアルゴリズムですがYOLOv3の後継にあたり、2020年6月に公開された最新のモデルです。YOLOv4という高精度化したYOLOv3の後継モデルもあるのですが、YOLOv5は推論処理時間がより速くなっているのが特徴です(精度はYOLOv4同等らしい)。YOLOv5は、検出精度と演算負荷に応じてs、m、l、xまでの4モデルがあります。詳細は↓。

YOLOv5はPyTorch※というディープラーニングフレームワークを用いています。PyTorchはシンプルなコードで動作し、さらに処理速度が高速ということもあり人気のフレームワークです。今回はPyTorchを動かすライブラリ導入も説明していきます。※FacebookのAIグループによって開発され、2017年にGithubのオープンソースとして公開
PyTorchでのプログラミングは必要ありませんが、興味ある方は↓の書籍がおすすめです。最近のアルゴリズム研究はPyTorchで実施することが多いようで、最新モデルはPyTorchで記述されていることが多い気がします。
今回はこのYOLOv5を使って、スナックエンドウの画像を検出できるか?挑戦していこうと思います。
- AI・機械学習を勉強したいけど、何からやればよいか分からない
- 書籍が難しすぎて挫折した
- これからデータサイエンティストを目指したい
- 物体検出が楽しそう
YOLOv5の様々な使い方について
当ブログではYOLOv5の様々な使い方を紹介しています。今回は独自データをつかったYOLOv5の学習方法についてですが、他にも様々な挑戦をしています。お時間あれば併せてご覧ください。
まずは、独自データで実装したい!という方は飛ばしてください👍
- ~動画検証編~スナックエンドウの収穫に物体検出をつかってみる





- Ultralystics社よりインタビューを受けた内容がブログになりました👍


YOLOv5モデル作成ステップ
- YOLOv5も環境設定からやっていきましょう。今回はYOLOv5のtrain.pyで実施されるファインチューニングが重いので、少しハイスペックなローカルPC環境で挑みます。
| 使用PCスペック | |
| OS | Windows 10 |
| CPU | AMD Ryzen 7 5800 |
| メモリ | 16 GB |
| GPU | GeForce RTX3070 |
- PCスペックが心配な方は、Google ColaboratoryであればGPUを使用できるのでそちらでの実行を挑戦してみてください。Google Colaboratory上でYOLOv5を動かしている例はググるとでてきますので参考にしてみてください(丸投げ)。※Google社が無料で提供している機械学習の教育や研究用の開発環境
- 環境設定としてAnacondaを使っていきますが、インストールについては前の記事を参考にしてください。
- 機械学習へGPUを認識させるために、少々面倒な環境設定があります。NVIDIA CUDA Toolkit、NVIDIA cuDNNをインストールする必要があるのですが、これらはGPUスペックによってインストールするバージョンがことなりますのでご注意ください。これらのインストールについては、こちらのサイトで細かく説明されており参考にさせていただきました。私の環境へインストールしたバージョンは下記です。後にインストールするPyTorchをYOLOv5を動作させるときCUDA 11.0以下ではうまくいかなかった(理由は分からず・・・)ので下記バージョンにしました。
- NVIDIA CUDA Toolkit 11.1.1
- NVIDIA cuDNN v8.2.0
YOLOv5のモデルは次のステップでつくっていきます。
- YOLOv5ソースコードの準備
- YOLOv5の仮想環境設定
- YOLOv5動作確認
- 学習前準備のあれこれ
- スナックエンドウの画像を使って学習実行
- 結果確認!
- YOLOv3とYOLOv5の比較
YOLOv5ソースコードの準備
YOLOv5をgithubからクローンしていきます。↓サイトからZipファイルをダウンロードしデスクトップへ展開してください。(やり方詳細は前記事と同様です。)
https://github.com/ultralytics/yolov5
YOLOv5の仮想環境設定
Anacondaを使って仮想環境をつくっていきます。スタートメニューから”Anaconda3”→”AnacondaPrompt”を起動し、↓のコードを実行してください。Pythonは3.8以降が必要ですので、ここで入れておきます。
conda create -n yolov5 python=3.8
conda activate yolov5 #環境アクティベート次に必要なライブラリを入れていきます。YOLOv5ディレクトリにrequirements.txtで指定されていますので、これらを入れていきます。Anaconda Promptへ↓コードを入れて実行してください。
cd Desktop\yolov5
pip install -U -r requirements.txtババーっと出てくると思います。しばらく待ちましょう。
このままでも学習を進められますが、GPUを使いたいのでGPU動作に適合したPyTorchを入れていきたいと思います。PyTorchの最新がv1.8.1(2021年5月時点)なのですが、最新バージョンだとうまく動かず。v1.7.1であればOKでした。↓のサイトから探せます。
PyTorch

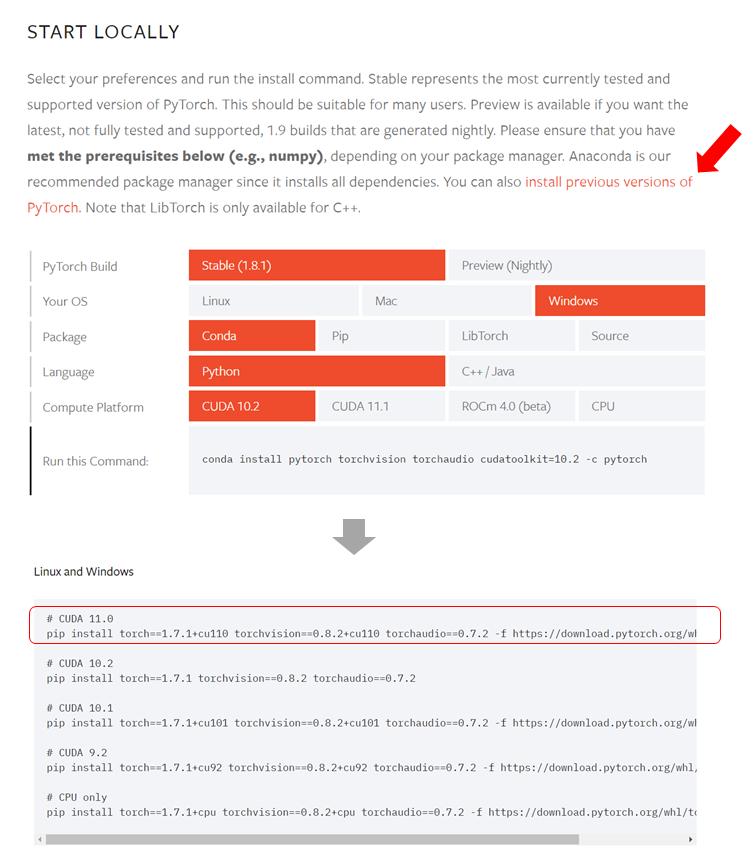
サイトより取得した↓のコードをAnacondaPromptで実行します。これで完了です。
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.htmlCUDAのバージョンに注意して、ご自身の環境にあったらモノをpipインストールしてください(condaだと何故かうまくいかず・・・)。
YOLOv5の動作確認
うまく環境構築できたか、動作確認をしていきましょう。YOLOv5ディレクトリにあらかじめ入っている画像を使って物体検出してみましょう。↓のコードをAnacondaPromptへ入力し実行してください。
python detect.py --source ./data/images/ --weights yolov5s.pt --conf 0.4引数の–sourceは画像の保存場所、–weightsはモデル重みデータ、–conf 0.4は確率値0.4以下は表示しないというコードです。実行するとruns/detect/expディレクトリへ物体検出結果の画像が保存されます。

うまく動作しているとこんな感じで画像が保存されたと思います。ワールドカップでの頭突き事件は記憶に新しいのですが、もう15年前ですか。。。
学習前準備のあれこれ
さて、いよいよスナックエンドウの画像をYOLOv5で学習していきたいと思います。
- データの配置
まずは画像のディレクトリ配置をやっていきましょう。↓のようにディレクトリを作成してください。スナックエンドウの画像を入れていきます。
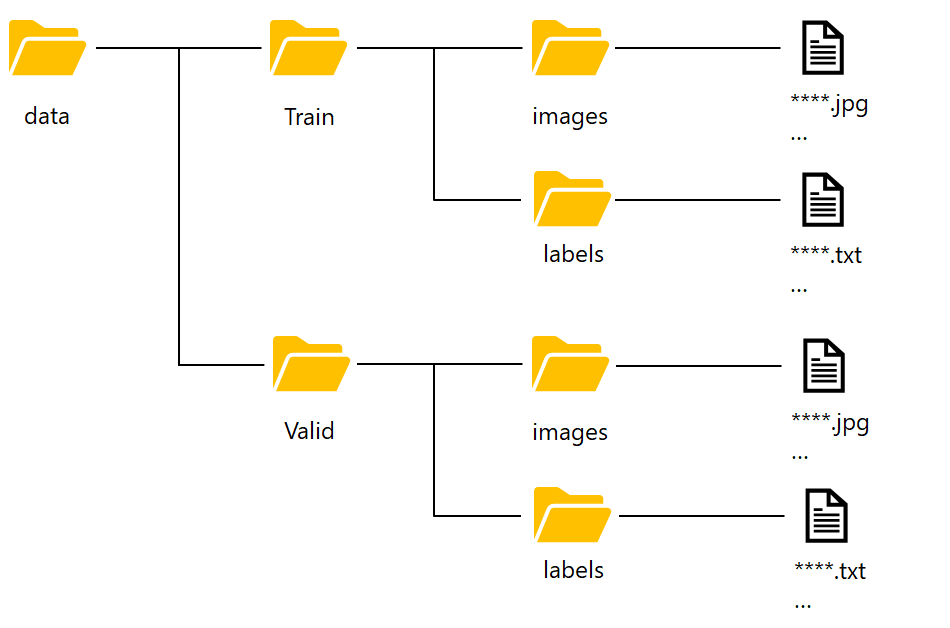
Trainフォルダは学習に使う画像および、アノテーションで、Validフォルダは検証用のデータを入れるフォルダとなっています。前の記事でスナックエンドウのアノテーションを実施しましたが、結果を.xmlファイルで保存していました。YOLOv5では.txt形式で読み込むため、変換していきます。方法は何でもいいですが、私はこのサイトの通りにやって変換しました。
- data.yamlファイル作成
dataディレクトリの中にcoco.yamlファイルというモノがあると思います。これをワードパッド等で開いてください。書いてあることを一度全部消します。↓を記入し、”data.yaml”というファイル名でYolov5フォルダ直下へ保存してください。
train: data/train/images
val: data/valid/images
nc: 1
names: [‘snack pea’]
以上で学習まえの準備あれこれは完了です。
スナックエンドウの画像を使って学習実行
さて、いよいよ学習していきましょう。コードは簡単です。↓をAnacondaPromptへコピペして実行してください。
python train.py --data data.yaml --cfg yolov5m.yaml --weights '' --batch-size 8 --epochs 1000引数–dataはデータの説明で画像の場所だったりラベルと紐付けをします。–cfgは最初のほうで説明した学習モデルs、m、l、xのどれを使うか?を指定します。今回はそこそこ処理が重く、そこそこ精度のよい”m”を使ってみます(yolov5m.yaml)。–epochsはデフォルトで300ですが、収束しなかったので1000まで上げました。実行するとババーっと文字が出てきてひたすら待ちです。
↓ここで私が発生したエラーを載せておきます。問題なく学習が進んでいる方は飛ばしてください。
ここで、私のPCだけか?わかりませんがメモリのOSエラー[WinError 1455]が発生しました。改善方法は仮想メモリーを増やすことで乗り切れました。やり方ですが、コントロールパネル→システムとセキュリティ→システム→システムの詳細設定を開いてください。詳細設定タブ→パフォーマンス設定→詳細設定タブ→仮想メモリ変更を押してください。仮想メモリをカスタムサイズへ変更していきます。
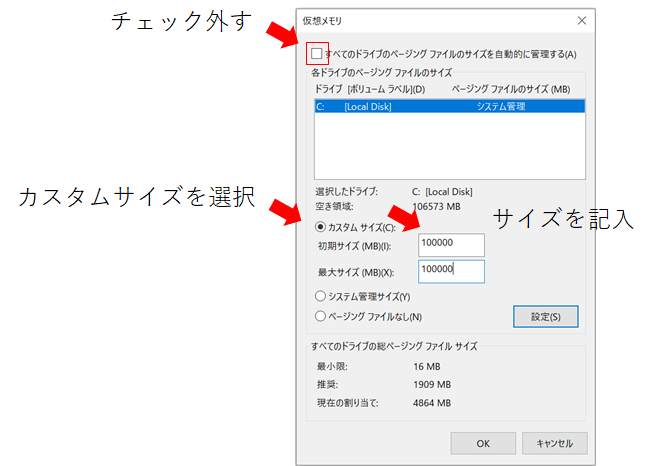
この設定で仮想メモリを増やしてエラー回避することができました。ただし、あくまで”仮想”なので恒久的にはメモリの増設を考慮した方が良いと思います。※注意!学習が終わったら元に戻しましょう。ディスク容量不足の警告がでます。
結果確認!
学習が完了するとruns/train/expディレクトリに結果が保存されます。”前処理のあれこれ”でValidディレクトリへ入れた画像の推定結果が保存されていると思います。確認してみましょう!

かなり良く物体検出されていると思います。数か所間違えたところも検出されていますが、だいたい合ってると思います。YOLOv5恐るべし・・・。太い茎と実を見分けるのが難しいようです。
学習モデルを使って、物体検出する方法を説明します。runs/train/exp/weightsにlast.pt、best.ptが入ってると思います。ここではbest.ptを重みファイルとして使います。best.ptをyolov5ディレクトリ直下へコピーしてください。できたら、↓のコードを実行してください。
python detect.py --source ./data/train/images/ --weights best.pt --conf 0.4ババーっと文字が出てきて落ち着くと、runs/detect/exp2/に物体検出結果がでてくると思います。この方法で新規画像でも物体検出することができます!
YOLOv3とYOLOv5の比較
epochs、lr等の条件が異なるので一概に比較できないのですが、気になると思うので比較してみます。

YOLOv5で検出力が高くなっていることがわかります。学習を進めていてもYOLOv5のロスが小さくなるので、うまく学習することができ、細部まで見極められている感じがあります。
さいごに
YOLOv5を実行してみた感想ですが、すごく簡単だと思いました。これは良い反面で学習時の細かいチューニングができないということなのですが、チューニングの必要なく良く学習するのが秀逸だと感じています。ぜひ一度、独自データで実践してみてください👍
こんなことができます!という動画をアップしています。良かったらご覧ください。
コメント
とてもわかりやすい記事をありがとうございます。この記事を参考に無事環境を組むことができました。GPUも認識され、実際学習中もメモリーが動いているのですが、GPUを使うと学習のLossがepoch0からnan値になってしまいます。画像サイズやバッチサイズを変更しても変わりがありませんでした。CPUのみの環境では何も発生しなかったのですが、ご教授いただければ幸いです。よろしくお願いいたします。
コメントありがとうございます。GPU環境でのみLossがnanになってしまうということですが、可能性としてはCUDA、cuDNN関連のセットアップであったり、PyTorchのGPU用ライブラリがうまくインストールされているか、この辺りに問題があるのでは?と思います。もし可能でしたら、CUDA・cuDNN関連の再インストールを実施し、環境を新たに構築しPyTorchなどのライブラリをインストールし、試してみてください。既に実施済みでしたらすみません。