

稲をよーく観察すると籾(もみ)に黒い斑点があるモノがあったりします。原因としていろいろあるようなのですが、いもち病という病気だったり、カメムシに養分を吸われた跡だったりするようです。中身がスカスカで籾殻しかない状態になったり、食べる分には問題ないのですが味が悪くなったりします。


このような状態の籾がどのくらいあるか、見た目で確認するのは疲れるのでAIの力で分類してみようと思います。前の記事でYOLOv5による籾の物体検出をやりました。実はこの時、黒い斑点をクラス分けしようと試みたんですが、うまく分類できませんでした(おそらく画像サイズが小さすぎたため・・・)。
YOLOv5で検出した籾の画像を切り出してEfficientNetで画像分類する!
今回のタスクは↑です。EfficientNetは強力な画像認識モデルと言われており、転移学習を簡単にできることで有名です。今回はこのアルゴリズムをつかっていこうと思います。
過去に実施したYOLOv5による籾の物体検出は↓です。次の学習データセット準備で物体検出結果を使いますので、併せてご覧ください。

EfficientNetについては↓に分かりやすい解説があります。こちらも併せてご覧ください。

学習環境
学習環境
- Windows 10
- CPU : AMD Ryzen 7 5800
- GPU : RTX3070 8GB
事前準備としてCUDA、cudnnのインストールします。この辺りはここに詳しく掲載されているので、その通りにインストールしています。インストールしたバージョンは下記です。
- NVIDIA CUDA Toolkit 11.4
- NVIDIA cuDNN v8.2.0
学習データセットの準備
今回分類したい画像は↓です。

左の画像をYOLOv5で学習させているので、右図のような籾の黒い部分を物体検出するのは難しいです。アノテーションが大変でサンプルサイズ稼げなかったのも原因と思いますが。。。
そこで、一旦全て物体検出してしまい、検出したバウンディングボックスを切り出して、切り出した画像を学習用データセットとしていきます。手順を説明します。
YOLOv5で推論した結果からバウンディングボックスを切り出すコードは↓YOLOv5の推論って!?という方はここを参照ください。
#images
python detect.py --source ./data/valid_ine/images/ --weights best.pt --conf 0.4 --save-crop引数として–save-cropを追加することでバウンディングボックスで切り出した画像を保存することができます。保存ディレクトリは./runs/detect/exp下にcropsというディレクトリが生成されます。↓の感じで画像が切り出されました。当然ですが画像サイズはまちまちなのであとで修正は必要です。
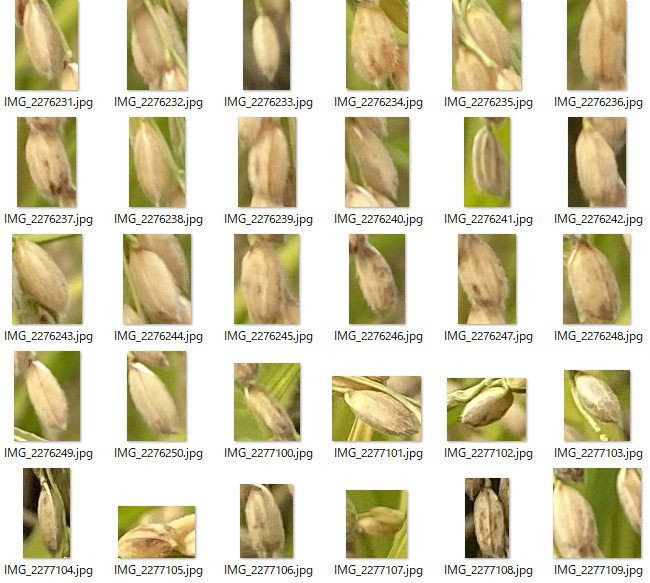
これを以下の基準で分類していきます。
- A:正常な籾
- B:多少黒い斑点のある籾(食べれそう)
- C:黒い斑点が多い籾、緑色の籾(食べられなさそう、スカスカになってそう)
分類した画像はディレクトリへ保存します。ディレクトリの配置は↓のようにそれぞれの分類に応じて分けて保存してください。
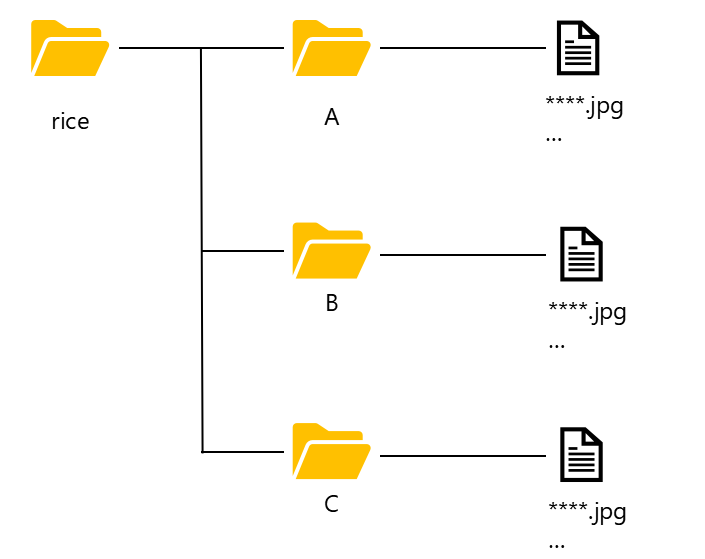
これで学習データセットの準備はOKです。
EfficientNetの実装
EfficientNetの実装はTensorFlowのチュートリアルをベースに実施していきます。ライブラリのバージョンは↓です。必要に応じインストールしてください。
- tensorflow-gpu 2.6.0
- tensorflow-hub 0.12.0
- matplotlib 3.4.2
- numpy 1.19.5
- keras 2.6.0
- seaborn 0.11.2
実装はAnacondaのJupyterNotebookを想定して記載します。必要あればインストールしてください。Anacondaって!?という方はここを参考にしてください。
コードを順に説明していきます。とにかく急いで実装したい!という方は最後にコードをまとめておきますので、そちらをご覧ください。
ライブラリのインポート
import numpy as np
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
import seaborn as sns学習データの画像リサイズ、クラスラベリング
TensorFlowの機能を使って学習データの準備をします。
- 画像サイズを64x64pixelへ統一
- 学習データを「訓練用(train_data)」と「検証用(val_data)」に分ける
- それぞれの画像へクラス(A, B,C)をラベリング
↓のコードで完了します。
IMAGE_SHAPE = (64, 64)
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255, validation_split = 0.3) #0.3を変更することでval_dataの枚数を変更可能です
train_data = image_generator.flow_from_directory("./rice/", target_size=IMAGE_SHAPE, subset = "training" )
val_data = image_generator.flow_from_directory("./rice/", target_size=IMAGE_SHAPE, subset = "validation" )Found 838 images belonging to 3 classes. Found 357 images belonging to 3 classes. #今回学習に使うデータ、クラス数です。上がtrain_data、下がval_data
for train_batch, train_label_batch in train_data:
print("train_Image batch shape: ", train_batch.shape)
print("train_Label batch shape: ", train_label_batch.shape)
break
for val_batch, val_label_batch in val_data:
print("val_Image batch shape: ", val_batch.shape)
print("val_Label batch shape: ", val_label_batch.shape)
breaktrain_Image batch shape: (32, 64, 64, 3) train_Label batch shape: (32, 3) val_Image batch shape: (32, 64, 64, 3) val_Label batch shape: (32, 3)
tensorflow-hubでモデルをダウンロード
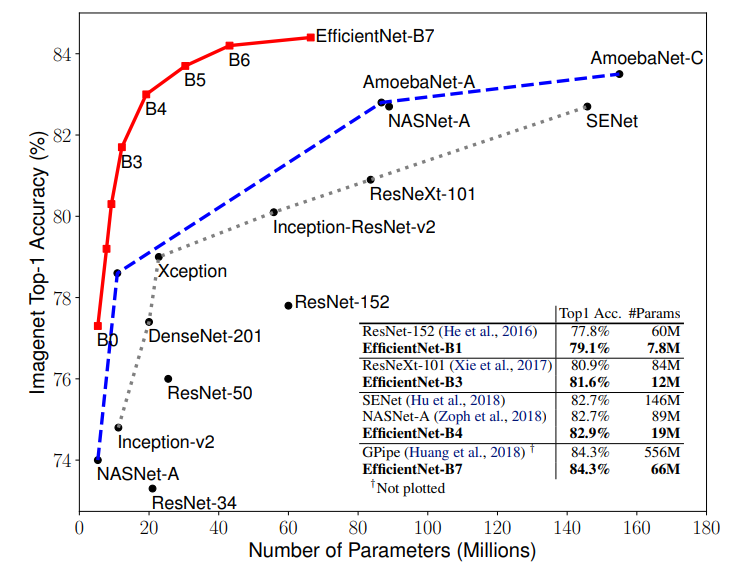
https://arxiv.org/abs/1905.11946
EfficientNetはモデルのパラメータ数と精度でB0~B7のモデルがあります。↑図の赤いグラフです。どのモデルをベースに転移学習をするか選択します。今回は「B0」モデルを選定しました。コードは↓。
feature_extractor_url = "https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1" #B0を選定
feature_extractor_layer = hub.KerasLayer(feature_extractor_url,
input_shape=(64,64,3))
feature_extractor_layer.trainable = False #学習済み重みは固定するのでFalseEfficientNetモデル構築
model = tf.keras.Sequential([
feature_extractor_layer,
layers.Dense(train_data.num_classes, activation='softmax')
])
model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1280) 4049564 _________________________________________________________________ dense (Dense) (None, 3) 3843 ================================================================= Total params: 4,053,407 Trainable params: 3,843 Non-trainable params: 4,049,564 _________________________________________________________________
学習プロセスのコンフィグをコンパイルします。多クラス分類なのでcategorical_crossentropyを使用します。
model.compile(
optimizer=tf.keras.optimizers.Adam(lr=0.01),
loss='categorical_crossentropy',
metrics=['acc'])学習実施!
epochs = 50
train_steps_per_epoch = np.ceil(train_data.samples/train_data.batch_size)
val_steps_per_epoch = np.ceil(val_data.samples/val_data.batch_size)
batch_stats_callback = CollectBatchStats()
history = model.fit(train_data, epochs=epochs,
steps_per_epoch=train_steps_per_epoch,
validation_data=val_data,
validation_steps=val_steps_per_epoch)学習の可視化
sns.set()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()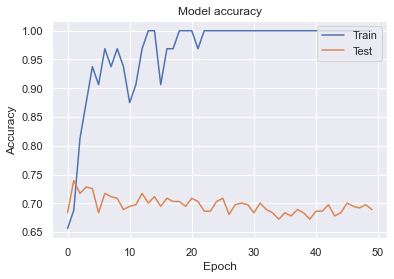
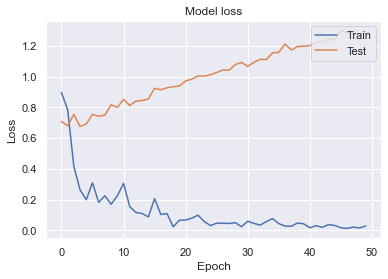
短時間で精度が高いモデルができました。(めっちゃ過学習してるのでチューニング必要ですが。。。)パラメータ数を抑えているためかResNetに比べて学習時間はかなり短いです。
推論結果の確認
val_dataを使って推論した結果を確認していきます。↓のコードを実行してください。
class_names = sorted(train_data.class_indices.items(), key=lambda pair:pair[1])
class_names = np.array([key.title() for key, value in class_names])
class_namesarray(['A', 'B', 'C'], dtype='<U1')
predicted_batch = model.predict(val_batch)
predicted_id = np.argmax(predicted_batch, axis=-1)
predicted_label_batch = class_names[predicted_id]
label_id = np.argmax(val_label_batch, axis=-1)
plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range(30):
plt.subplot(6,5,n+1)
plt.imshow(val_batch[n])
color = "green" if predicted_id[n] == label_id[n] else "red"
plt.title(predicted_label_batch[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (green: correct, red: incorrect)")
そこそこですかね。あとは籾のクラス数を数えることで不良率を割り出せると思います。YOLOv5とEfficientNetを連動させ稲の出来を判定するツールとして有用ではないでしょうか!?
EfficientNetをつかった画像認識はすごく簡単に実装でき、学習時間も他のアルゴリズムに比べ軽いモデルです。是非お試しあれ👍
EfficientNetモデル精度を上げるブログを書きました。↓こちらも併せてご覧ください👍

全コード
import numpy as np
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
import seaborn as snsIMAGE_SHAPE = (64, 64)
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255, validation_split = 0.3)
train_data = image_generator.flow_from_directory("./rice/", target_size=IMAGE_SHAPE, subset = "training" )
val_data = image_generator.flow_from_directory("./rice/", target_size=IMAGE_SHAPE, subset = "validation" )for train_batch, train_label_batch in train_data:
print("train_Image batch shape: ", train_batch.shape)
print("train_Label batch shape: ", train_label_batch.shape)
break
for val_batch, val_label_batch in val_data:
print("val_Image batch shape: ", val_batch.shape)
print("val_Label batch shape: ", val_label_batch.shape)
break#B0を選定
feature_extractor_url = "https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1"
feature_extractor_layer = hub.KerasLayer(feature_extractor_url,
input_shape=(64,64,3))
feature_extractor_layer.trainable = False
model = tf.keras.Sequential([
feature_extractor_layer,
layers.Dense(train_data.num_classes, activation='softmax')
])
model.summary()model.compile(
optimizer=tf.keras.optimizers.Adam(lr=0.01),
loss='categorical_crossentropy',
metrics=['acc'])
epochs = 50 #エポック数は任意で設定してください
train_steps_per_epoch = np.ceil(train_data.samples/train_data.batch_size)
val_steps_per_epoch = np.ceil(val_data.samples/val_data.batch_size)
batch_stats_callback = CollectBatchStats()
history = model.fit(train_data, epochs=epochs,
steps_per_epoch=train_steps_per_epoch,
validation_data=val_data,
validation_steps=val_steps_per_epoch)sns.set()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()class_names = sorted(train_data.class_indices.items(), key=lambda pair:pair[1])
class_names = np.array([key.title() for key, value in class_names])
class_namespredicted_batch = model.predict(val_batch)
predicted_id = np.argmax(predicted_batch, axis=-1)
predicted_label_batch = class_names[predicted_id]
label_id = np.argmax(val_label_batch, axis=-1)
plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range(30):
plt.subplot(6,5,n+1)
plt.imshow(val_batch[n])
color = "green" if predicted_id[n] == label_id[n] else "red"
plt.title(predicted_label_batch[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (green: correct, red: incorrect)")関連書籍
ディープラーニングやお米の栽培で参考書籍を紹介します。バケツでも栽培できるようなので気になる方は是非やってみてください👍
画像/動画撮影はiphone11ですが、できるだけブレないように三脚・グリップで固定して使っています。関連機材を紹介します
コメント
はじめまして。
このようなお問い合わせは適切かどうか恐縮なのですが、、、。
この実装を個人教授で1日くらいご指導いただけませんでしょうか?もちろん御礼を用意いたします。
zoomでも、どこかに出向いてもどちらでも。
また、それが難しいなら、どこかのスクールかどなたかのご紹介でも構いません。
よろしくおねがいします。
こんにちは。
コメントありがとうございます。
申し訳ございませんが、指導などはおこなっておりません。
というか私は独学でここまでやってますので、書籍などを基に独自のデータで実装してみることをおススメします。
おススメの書籍は↑記事でご紹介しています。
お力になれずすみませんが、頑張ってみて下さい。
Nukui@FarmL