

この前(2022年6月)YOLOv6が出たと思ったら、2022年の7月にYOLOv7が公開されました。今回はYOLOv7を使ってオリジナルデータの学習と推論に挑戦してみます。また、YOLOv5lモデルとも比較してみます👍
YOLOv7はYOLOv5と非常に似ているので、YOLOv5で学習した経験があれば簡単に実装することができると思います。FarmLブログではYOLOv5の学習・推論について詳しく説明していますので、それをベースに実装していきます👍
YOLOv5の学習については↓の記事で詳しく説明しています。


YOLOv6はこちら↓。こちらも活用していくので併せてご覧ください。

YOLOv7とYOLOv5の比較
まずはYOLOv7とYOLOv5の比較をしてみます。
YOLOv7とYOLOv5lのモデルで比較しています。
YOLOv7はYOLOv5と学習の難易度は同じくらい簡単かつ、高精度に物体検出できることが分かります。よく見ると、YOLOv5で未検出のスナップエンドウを検出しており、感度は良さそうです。一方で、誤検出も目立つかな?と思います。
すみませんが、検出速度に関しては今回は未検証です😅
COCOデータセットの重みデータでの比較もやってみました。
YOLOv7の方が遠くの人を検出できており、感度良いですね👍
以下に、YOLOv7をローカルPCで動かした方法を記載します。
YOLOv7について
YOLOv7のアーキテクチャについては論文が公開されているので参考にしてみてください↓

↓日本語で論文解説もされています。

YOLOv7は速度/精度面において、既知の物体検出モデルを上回る結果となっています。YOLOv5と比較するとFPSで120%ほど速くなっているとのことでした↓
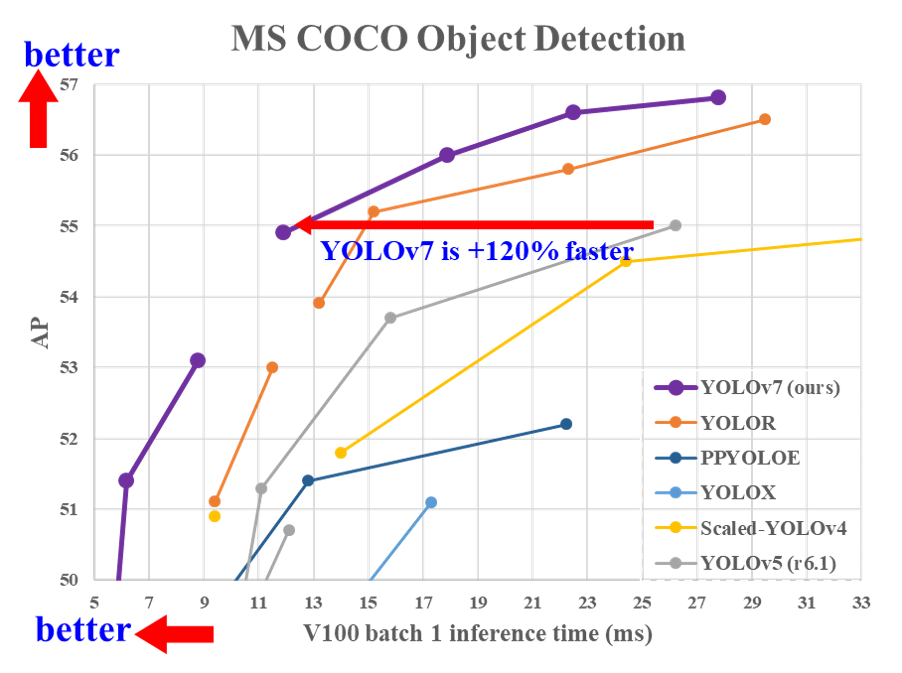
FarmLブログで取り扱う農作物データでも同様か?ということで試してみます👍
YOLOv7の学習準備
学習環境
GPU搭載したローカルPCの環境で実装していきます。GPU環境のない方はGoogle Colabなどの利用をお勧めします。CPU環境ではしんどいです😂
- OS : Windows 11
- CPU : AMD Ryzen7 5800
- メモリ : 16GB
- GPU : GeForce RTX3070 8GB
CUDAやライブラリ関連は過去の記事と同じ環境で実施していきます。ここを参照してください。
インストール
ソースコードは↓を使っていきます。
AnacondaPromptなどで↓のコードを実行してください。過去の記事でYOLOv5は手動でZIPファイルをダウンロードしていますが、同じことですのでやりやすい方を選択してください。
git clone https://github.com/WongKinYiu/yolov7
cd YOLOv7
pip install -r requirements.txtPyTorchは1.8.1+cu111で動作確認しました。
学習データの準備
学習データの準備についてはYOLOv6と同様でやっていきます👍↓に詳細がありますので併せてご覧ください。
データセットの準備
物体検出用のデータセットを準備します。データセットは検出する物体に対しアノテーションという処理を実施し学習する必要があります。
独自のデータを準備しアノテーションを実施してください。アノテーションに“labelimg”を使う場合はYOLO形式(.txt)で保存してください。
今回(も)↓のようなスナップエンドウの画像を使っていきます。
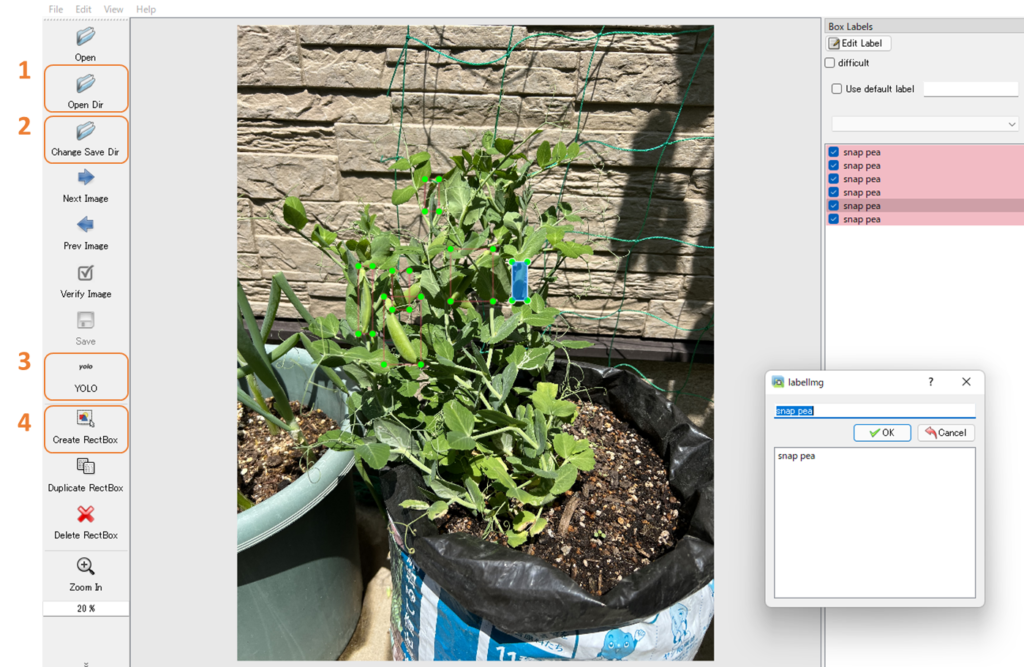
- 画像データを保存してあるフォルダを指定する
- アノテーションしたデータを保存するフォルダを指定する
- YOLOフォーマットを指定する
- 物体検出したいモノをアノテーションして、保存する
データの配置
作業フォルダ直下にcustom_datasetフォルダを作成します。アノテーションしたデータセットを↓のように配置してください。
custom_dataset
├── images
│ ├── train
│ │ ├── train0.jpg
│ │ └── train1.jpg
│ └── val
│ ├── val0.jpg
│ └── val1.jpg
└── labels
├── train
│ ├── train0.txt
│ └── train1.txt
└── val
├── val0.txt
└── val1.txtYAMLファイルをつくる
dataset.yamlファイルを作成していきます。dataフォルダ内にdataset.yamlファイルが格納されていると思います。この中身を↓のように修正してください。
# Please insure that your custom_dataset are put in same parent dir with YOLOv7_DIR
train: ./custom_dataset/images/train # train images
val: ./custom_dataset/images/val # val images
# test: ./custom_dataset/images/test # test images (optional)
# Classes
nc: 1 # number of classes
names: ['snap_pea'] # class namesdataset.yamlファイルを作成したら、dataフォルダへ保存してください。学習データの準備は以上でOKです。
YOLOv7で学習してみる
事前学習済み重みデータを準備する
GitHub中段の”Transfer learning”に重みデータ(****.pt)があるのでダウンロードしてください。今回は”yolov7_training.pt”を使います。ダウンロードしたら、作業フォルダ直下にweightsフォルダを作成し、そこへ保存してください。
学習
下のコードをAnacondaPromptなどで実行して学習します。
python train.py --workers 8
--device 0
--batch-size 8
--data data/dataset.yaml
--img 640 640
--cfg cfg/training/yolov7.yaml
--weights './weights/yolov7_training.pt'
--name yolov7_snap_pea
--hyp data/hyp.scratch.p5.yaml引数の詳細はtrain.pyの中身に記載されているのでご確認ください。
学習結果は”runs/train/yolov7_snap_pea”フォルダの中に格納されます。
ハイパーパラメータ進化
YOLOv5でハイパーパラメータ進化ができましたが、YOLOv7でもできます。
- 上で学習した重みデータ(best.pt)をweightsフォルダへ移動
- –evolveを追加
python train.py --workers 8
--device 0
--batch-size 8
--data data/dataset.yaml
--img 640 640
--cfg cfg/training/yolov7.yaml
--weights './weights/snap_yolov7_best.pt'
--name yolov7_evolve
--hyp data/hyp.scratch.p5.yaml
--evolve出力(yolov7_evolve)フォルダにhyp_evolved.yamlが格納されていると思います。これが進化後のパラメータなので、これを使って再度学習させればOKです👍(–hyp の後のパスを書き換えればOKです)
YOLOv7学習結果
学習結果の出力フォルダ(”runs/train/yolov7_snap_pea”)の中に結果が格納されているので確認していきます。
YOLOv7学習結果
Results.pngを見ていきます。
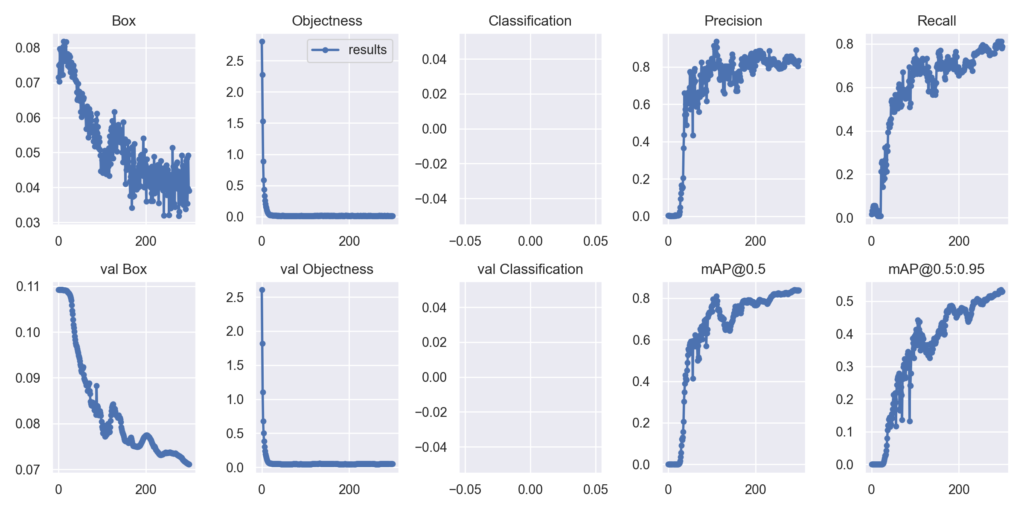
Box、Objectnessのロスが下がっており学習が進行しているのが分かります👍
最終的に精度はmAP@0.5:0.83となりました。特別難しい調整などなく、高精度なモデルが得られたと思います👍
YOLOv5学習結果との比較
YOLOv5の結果を↓に示します。mAP@0.5は0.85とYOLOv7と比較し若干良い結果となっています。
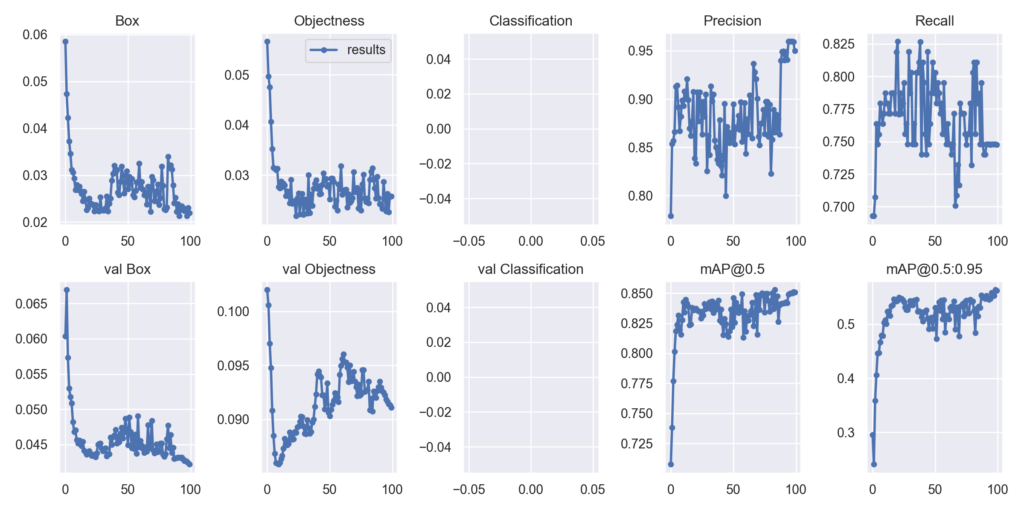
Precision/RecallをYOLOv7と比較は↓
| Model | Precision | Recall |
| YOLOv7 | 0.83 | 0.79 |
| YOLOv5 | 0.95 | 0.75 |
RecallはYOLOv7が優れており、PrecisionはYOLOv5の方が優れていることが分かります。
YOLOv7は感度高いですが、一方で間違えたモノでも多く検出していたのはRecallが高く見逃しが少ないモデルとなっているためと考えられます。
どちらのモデルが優れているか?は使い方次第なので言えませんが、私はYOLOv5の方が好きですかね🚀🚀🚀
YOLOv7で学習した重みを使って推論する
↓のコードを実行すると推論してくれます。画像や学習済み重みのパスはご自身の環境に合わせ指定してください。
python detect.py --source ./data/inference/ #推論したい画像のパスを指定
--weights ./runs/train/exp/weights/last.pt #学習した重みを指定
--conf 0.3
--line-thickness 6 #バウンディングボックスの線の太さ。入力画像に応じお好みで変えてください推論結果は./runs/detect下に保存されます。
いい感じの物体検出ができました👍

YOLOv5の様々な使い方について
FarmLブログではYOLOv5の様々な使い方を紹介しています。お時間あれば併せてご覧ください。
- 独自データをつかったYOLOv5の学習方法
- 事前学習済みデータを転移学習したYOLOv5の学習方法
- 遺伝的アルゴリズムを利用したYOLOv5のパラメータ最適化手法

- YOLOv5で物体検出した画像を切り出して学習データにする方法

- YOLOv5で物体検出した作物の数を数える【Object Counter】

- Ultralystics社よりインタビューを受けた内容がブログになりました👍


コメント
学習環境のGPUの部分、RTX3700になってます!
のーすさん
ありがとうございます。修正しました。