

2022年6月、新しく「YOLO」の名の付くモデルYOLOv6が公開されました。”YOLOv6″という名前ですが、Ultralytics社の”YOLOv5″からのバージョンアップではなく、Meituan Technical Teamによる異なるアルゴリズムでの開発となっています。YOLOv6のネーミングについてはここにコメントがありました。
FarmLブログでは多くのYOLOv5の記事を掲載してきましたが、今回はYOLOv6を試してみます。YOLOv6を使ったオリジナルデータの物体検出です👍
折角なのでYOLOv5との比較もやってみます👍今回はハイパーパラメータのチューニングはやらず、デフォルト設定で比較していきます。
YOLOv6について
YOLOv6の特徴は?というと「速度」と「精度」とのことです。物体検出にとって速度は重要で、特にリアルタイムで検出する場合はどのくらいのFPSで処理できるか?というのは多くの開発者にとって、そのアルゴリズムを使う重要なポイントになっていると思います。
COCOval2017データセットでの各アルゴリズム性能比較結果が↓です。
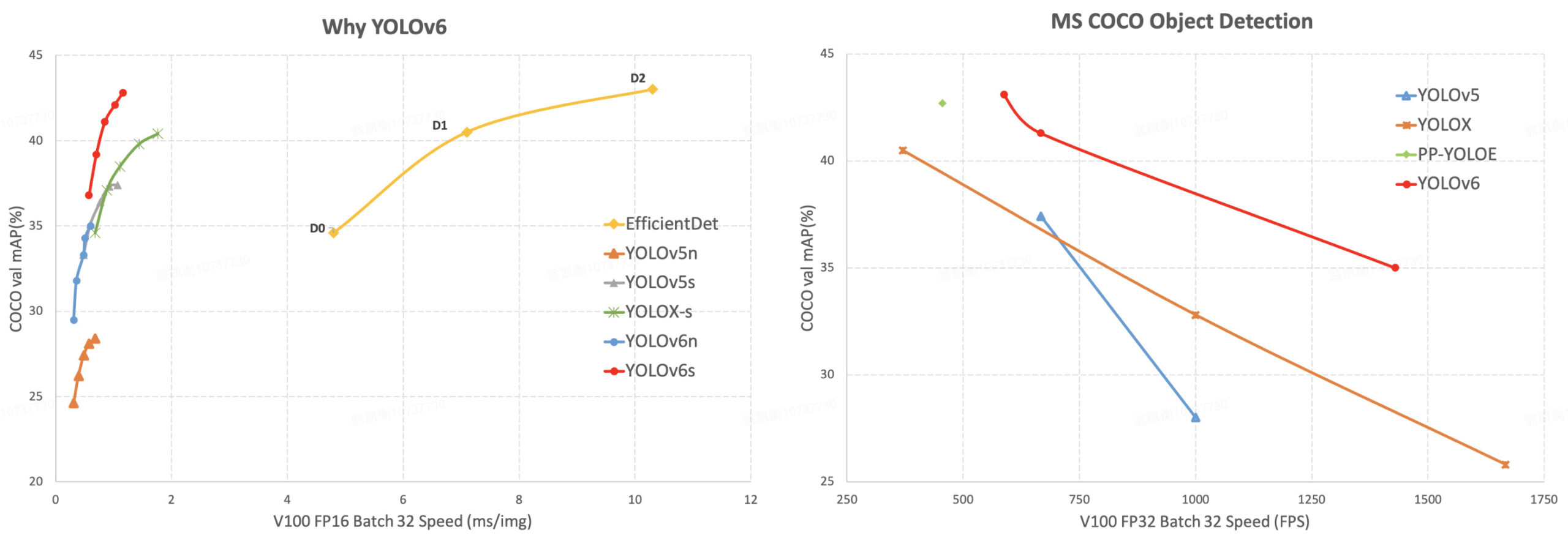
左の図が単一画像の推論結果ですが、YOLOv6sがYOLOv5sよりも精度が高くなっているのが分かります。EffieientDetとは大きなギャップがみられます。
右の図はビデオの推論結果ですが、ここでもYOLOv6が高精度となっています。
ホントか⁉️ということでオリジナルデータで検証してみます👍FarmLブログではいろんな野菜の物体検出を実施してきていますので、そのデータを使っていきます
YOLOv6を実装する
学習環境
GPU搭載したローカルPCの環境で実装していきます。GPU環境のない方はGoogle Colabなどの利用をお勧めします。CPU環境ではしんどいです😂
- OS : Windows 11
- CPU : AMD Ryzen7 5800
- メモリ : 16GB
- GPU : GeForce RTX3070 8GB
CUDAやライブラリ関連は過去の記事と同じ環境で実施していきます。ここを参照してください。
インストール
ソースコードは↓を使っていきます。
AnacondaPromptなどで↓のコードを実行してください。PyTorchはv1.8をインストールしてください。
git clone https://github.com/meituan/YOLOv6
cd YOLOv6
pip install -r requirements.txt※そのまま実行するとPyTorch v1.12(2022/7現在)がインストールされ、強行したらエラーでました。PyTorchはv1.8.1へダウングレードすると上手くいきました。
推論してみる
上手く動くか、ひとまず推論してみます。まずはpretrained weightをダウンロードします。ここでは”yolov6s.pt”をダウンロードしました。作業フォルダにweightsという新しいフォルダを作成し、そこへダウンロードした”yolov6s.pt”を保存します。
↓のコードを入れ実行してください。
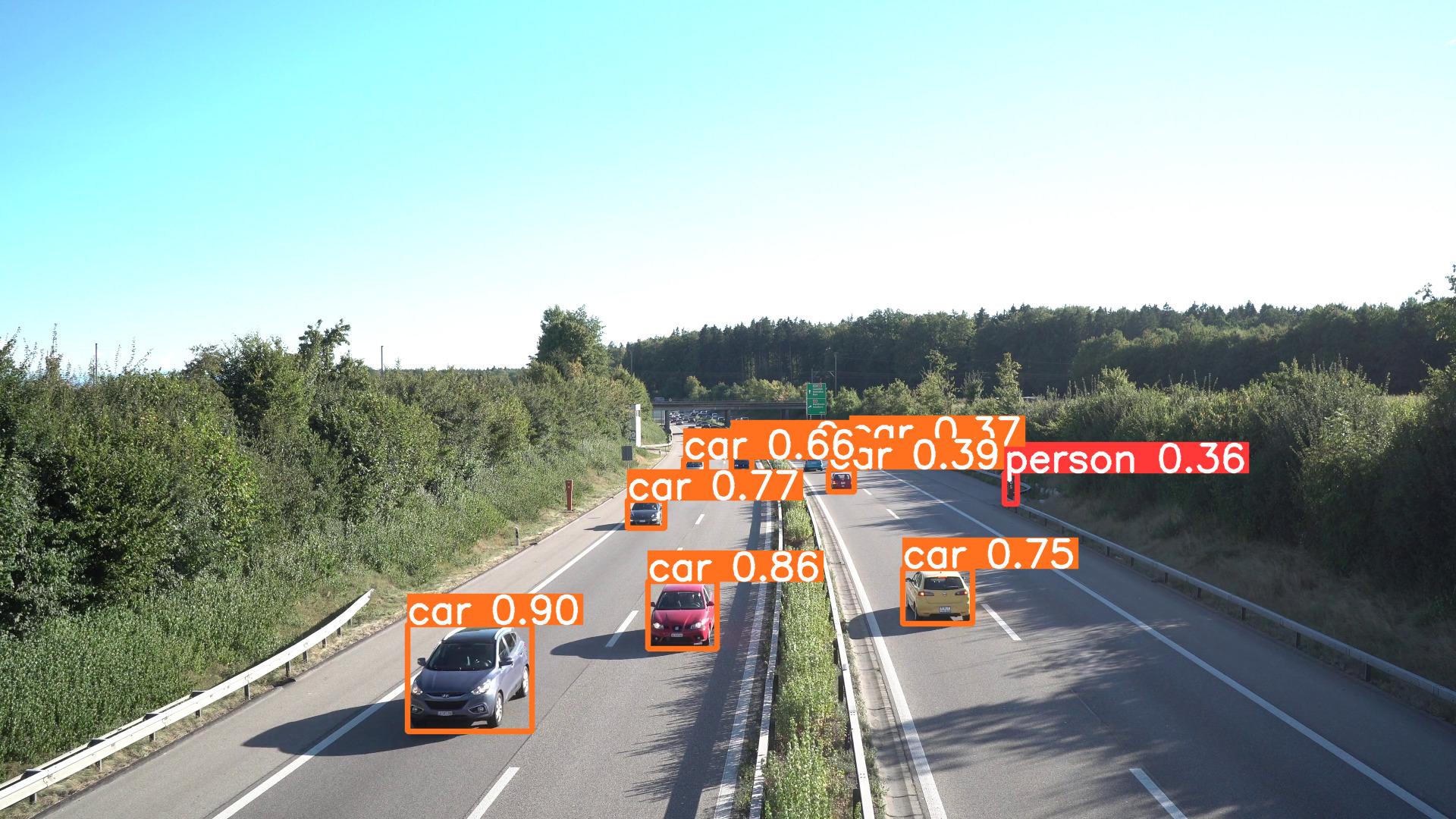
python tools/infer.py --weights weights/yolov6s.pt --source data/images/処理が完了し、runs/inference/expフォルダの中に物体検出された画像↓が出力されればOKです。

ダウンロードした”yolov6s.pt”はCOCO val2017 datasetを事前学習した重みデータですので、このままでもいろいろな物体を検出することができます。試しにいろいろやってみても面白いです👍

YOLOv6でオリジナルデータを学習する
データセットの準備
物体検出のデータセットは、検出する物体に対しアノテーションという処理を実施し学習する必要があります。アノテーションは“labelimg”を使って、こことかここでアノテーションした手法と同じ方法でアノテーションしていきます。アノテーションデータはYOLO形式(.txt)で保存してください。↓の感じです。
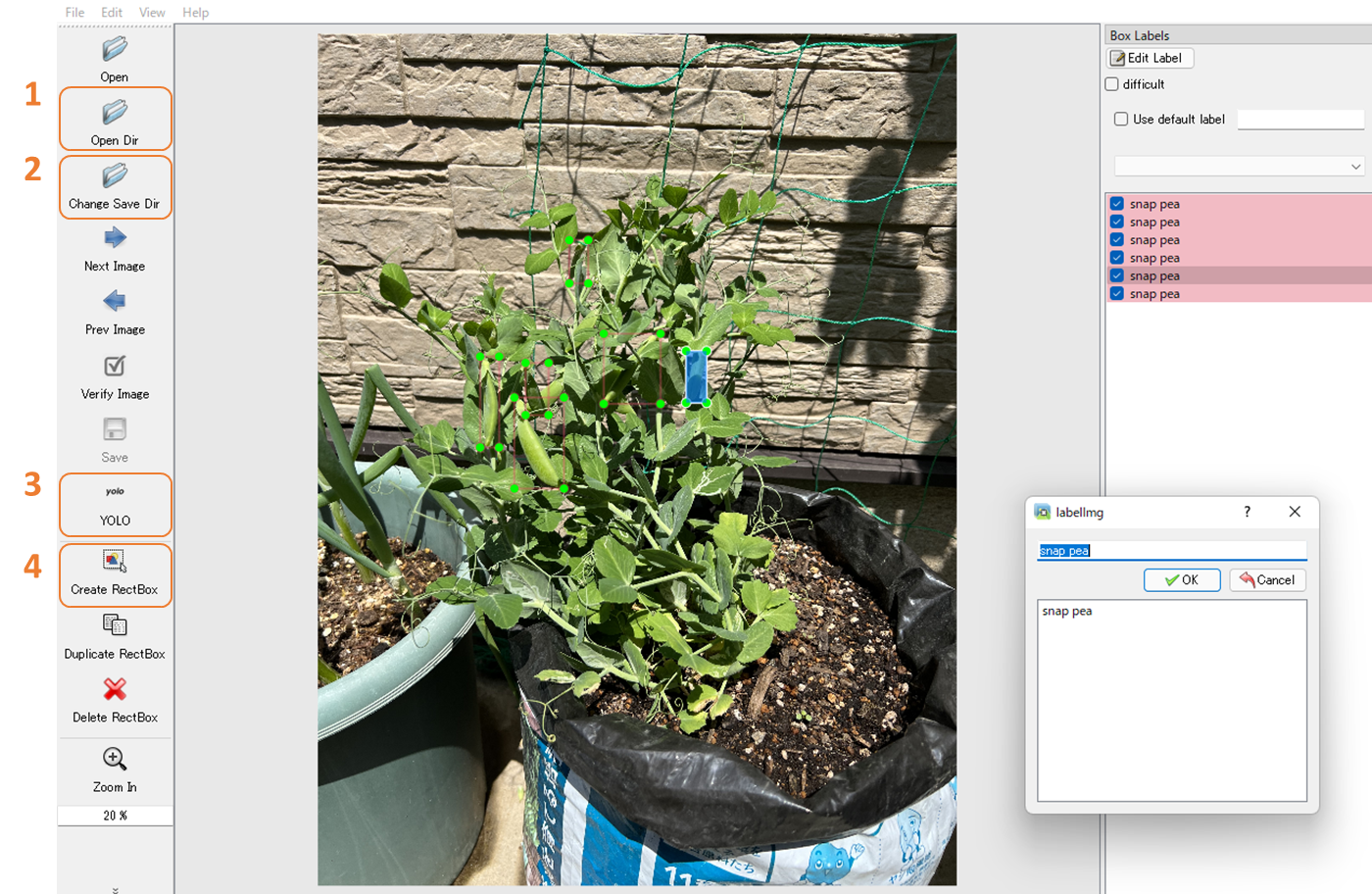
- 画像データを保存してあるフォルダを指定する
- アノテーションしたデータを保存するフォルダを指定する
- YOLOフォーマットを指定する
- 物体検出したいモノをアノテーションして、保存する
データの配置は↓のようにしてください。作業フォルダ直下にcustom_datasetフォルダを配置してます。
custom_dataset
├── images
│ ├── train
│ │ ├── train0.jpg
│ │ └── train1.jpg
│ ├── val
│ │ ├── val0.jpg
│ │ └── val1.jpg
│ └── test
│ ├── test0.jpg
│ └── test1.jpg
└── labels
├── train
│ ├── train0.txt
│ └── train1.txt
├── val
│ ├── val0.txt
│ └── val1.txt
└── test
├── test0.txt
└── test1.txtYAMLファイルをつくる
dataフォルダ内にdataset.yamlファイルが格納されていると思います。この中身を↓のように修正していきます。
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR
train: ./custom_dataset/images/train # train images
val: ./custom_dataset/images/val # val images
test: ./custom_dataset/images/test # test images (optional)
# Classes
nc: 1 # number of classes
names: ['snap_pea'] # class names
画像データセットのパスを設定し、分類クラス数、名前を変更していきます。今回はスナップエンドウの物体検出のみなのでクラス nc: 1 です。
事前学習済み重みデータを準備する ※”推論してみる”で実施していればとばしてください
重みデータを準備していきます。ここでダウンロードできるのでお好きな重みをダウンロードしてください。今回は”yolov6s.pt”をダウンロードします。
ダウンロードしたら作業フォルダ直下に”weights”フォルダを作成し、そこへ保存します。これでOKです。
学習する!
下のコードをAnacondaPromptなどで実行して学習します。これだけでOKです👍簡単ですね。
python tools/train.py --batch-size 6 --conf-file configs/yolov6s_finetune.py --data-path data/dataset.yaml --epochs 1000学習結果は”runs/train/expフォルダの中に格納されます。
YOLOv6で学習した重みを使って推論する
推論は上の方で説明した”推論してみる”と一緒です。weightsだけ今回学習したモノにパスを通せばOKです。↓のコードをAnacondaPromptなどで実行してください。
python tools/infer.py --weights runs/train/exp/weights/last_ckpt.pt --source custom_dataset/images/test/推論結果はruns/inference/expフォルダの中に格納されるので確認してみます



こんな感じでうまく推論できました👍
YOLOv6s vs YOLOv5s
同じ学習データセットを用いてYOLOv5sモデルで学習した結果と比較してみます。
| model | size(pixel) | mAP@0.5 | mAP@0.50:0.9 | FPS | Parameters(M) |
| YOLOv6s | 640 | 0.6238 | 0.3150 | 4.41 | 17.2 |
| YOLOv5s | 640 | 0.8111 | 0.4522 | 21.7 | 7 |
YOLOv5sの方が精度良さそうですし、予測速度も速いですね😅
オリジナルデータを使うとYOLOv5sの方が良いのでしょうか。画像でも確認してみます。

画像で確認してもYOLOv5sの方が良く検出できています。
動画でも確認してみました。
YOLOv6sはちらついています(物体検出がブレている)が、YOLOv5sは良い感じです。YOLOv5sとYOLOv6sを比較すると、現状はYOLOv5sの方が良さそうです😅
まとめ
YOLOv5の方が高精度モデルとなりました。YOLOv5は精度だけでなくパラメータチューニングなど優れた機能が装備されており成熟した使いやすいモデルだと思います。
一方でYOLOv6は、もっと大きなパラメータのモデルYOLOv6m/l/xなどもこれからリリースが予定されており、これからかな⁉という印象でした。
YOLOv5の様々な使い方について
FarmLブログではYOLOv5の様々な使い方を紹介しています。お時間あれば併せてご覧ください。
- 独自データをつかったYOLOv5の学習方法

- 事前学習済みデータを転移学習したYOLOv5の学習方法

- 遺伝的アルゴリズムを利用したYOLOv5のパラメータ最適化手法

- YOLOv5で物体検出した画像を切り出して学習データにする方法

- YOLOv5で物体検出した作物の数を数える【Object Counter】

- Ultralystics社よりインタビューを受けた内容がブログになりました👍
.webp)

コメント