

YOLOv5をつかって色々な作物を物体検出してきました。作物を育てる上で重要なことの一つは収穫量ですよね。ですが、実際作業してみると分かると思いますが、いちいち育った作物の数を数えるのは面倒であったり、そもそも夏場の炎天下では無理な作業になります。そこで今回は、YOLOv5で物体検出したバウンディングボックスを数えることで解決していこうと思います。
バウンディングボックスを数える方法はいくつかありますが、今回は画像or動画へ直接表示させるようにPythonスクリプトを少しいじっていこうと思います。
YOLOv5のGithubはこちらです↓
YOLOv5の様々な使い方について
当ブログではYOLOv5の様々な使い方を紹介しています。お時間あれば併せてご覧ください。
- 独自データをつかったYOLOv5の学習方法

- 事前学習済みデータを転移学習したYOLOv5の学習方法

- 遺伝的アルゴリズムを利用したYOLOv5のパラメータ最適化手法

- YOLOv5で物体検出した画像を切り出して学習データにする方法

前準備
今回は過去に実施した「トマトの物体検出器をつくってみた」のモデルと、「お米の物体検出をやってみる」のモデルをつかっていこうと思います。トマトのモデルできちんと数を数えられているかの確認をして、お米はどこまで多くのバウンディングボックスを数えられるか確認していこうと思います。
基本的にモデルは何でも大丈夫ですので、お手持ちのモノやGithubのチュートリアルでも大丈夫です。
実装環境はローカルPC(Windows10)です。詳細はここを参照してください。
detect.pyスクリプトの書換え
物体検出数を表示する考え方はすごくシンプルです。そもそもYOLOv5で物体検出をする際にバウンディングボックスの数を数えています。その情報をつかってOpenCVで文字を画像もしくは、動画中へ描写しているだけです。
っと理屈は簡単ですがYOLOv5のスクリプトは複雑なので、どこへコードを書けばいいか難しいですよね。以下にスクリプトの書換え手順を説明します。
- YOLOv5作業ディレクトリにあるdetect.pyをひらく
- detect.pyの中で”# Write results”を見つける
- “save_one_box(xyxy, imc, file=save_dir / ‘crops’ / names[c] / f'{p.stem}.jpg’, BGR=True)”コードの下へ↓のコードを追記する
# Write resultsのfor文に入るように記述してください
# Print counter
n_1 = (det[:, -1] == 0).sum() #ラベルAの総数をカウント
a = f"{n_1} "#{'A'}{'s' * (n_1 > 1)}, "
cv2.putText(im0, "Tomato counter " , (20, 50), 0, 1.0, (71, 99, 255), 3)
cv2.putText(im0, "A : " + str(a), (20, 100), 0, 1.5, (71, 99, 255), 3)
n_2 = (det[:, -1] == 1).sum() #ラベルBの総数をカウント
b = f"{n_2} "#{'A'}{'s' * (n_1 > 1)}, "
cv2.putText(im0, "B : " + str(b), (20, 150), 0, 1.5, (0, 215, 255), 3)
n_3 = (det[:, -1] == 2).sum() #ラベルCの総数をカウント
d = f"{n_3} "#{'A'}{'s' * (n_1 > 1)}, "
cv2.putText(im0, "C : " + str(d), (20, 200), 0, 1.5, (154, 250, 0), 3)- スクリプトをdetect_2.pyへ名前を変えて保存する (名前は何でもいいです。)
- detect_2.pyをつかって物体検出を実行する
上記の手順で画像or動画の左上にカウンターが表示されるようになります。
追加したスクリプトの説明
n_1 = (det[:, -1] == 0).sum()
ラベルの数を数えています。==0で0番目のラベルを数えるので、指定したいラベルの数値へ変えることでいろいろ表示することができます。
cv2.putText(im0, "A : " + str(a), (20, 100), 0, 1.5, (71, 99, 255), 3)
OpenCVというライブラリのputTextで文字を画像or動画中へ描写しています。im0は入力画像なのでそのままにしておきましょう。str(a)でカウント数が表示されるようになっています。後半の数値で表示される位置、フォントサイズ、文字色などを調整することができます。putTextの詳しい説明はこの辺りを参照すると良いと思います。
物体検出数のカウント出力
python detect_2.py --source ./data/train/images/ --weights best.pt --conf 0.4detect_2.py(上記を追記したスクリプト)を選択することで物体検出のカウンターが表示されるようになります。
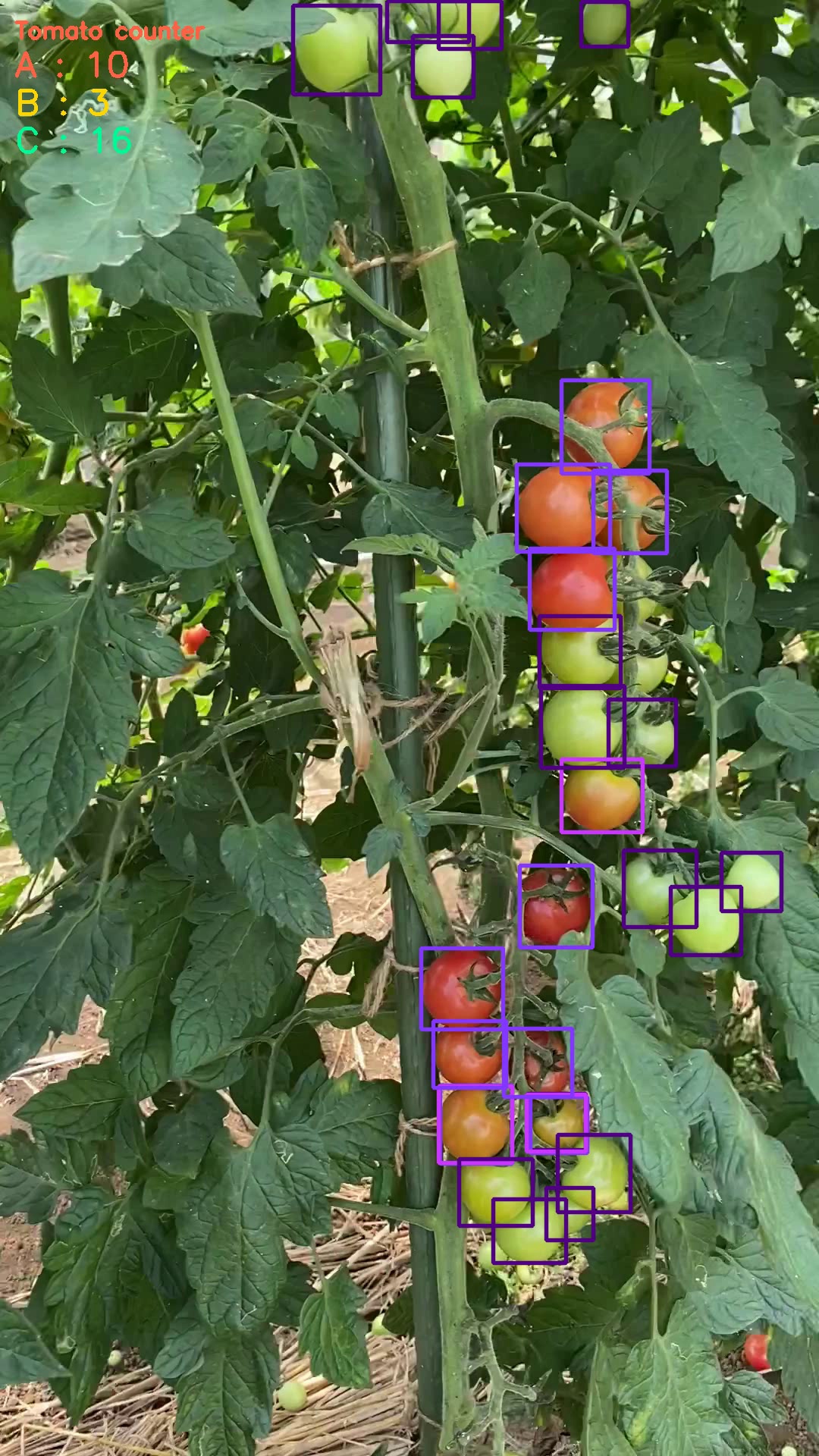
トマトのモデルでやってみる
トマトでやってみると↓の感じです。いい感じでカウントできていると思います。
お米のモデルでやってみる
お米の物体検出モデルでもやってみます。ここで注意ですが、デフォルトの設定だとバウンディングボックスは300個までしかカウントできない仕様となっています。
カウンターの限界突破をやっていきます。作業ディレクトリ /utils/general.pyを開いてください。↓のコードを書き換えればOKです。今回は3000個までカウントできるように設定します。
max_det = 300 # maximum number of detections per image オリジナルコード
↓
max_det = 3000 # maximum number of detections per image 変更コード※2022/5/15追記 カウンターの数は’–max-det’で指定できるようになりました。↑の作業は不要です。
カウント数を設定後、お米の動画でやってみると↓の感じです。

お米のような数の多い穀物については、大まかな収穫量を知る際に有効な手段かな?と思います。
動画も↓にアップします。早すぎて分かりにくいですがアバウトに数を把握したい場合は結構使えるんじゃないでしょうか?!👍
以上、簡単なスクリプト変更だけでカウンターを表示する方法でした。面白いので是非やってみてください。
いろいろな動画で試してみました。↓も併せてご覧ください。

関連書籍・撮影機材
ディープラーニングやお米の栽培で参考書籍を紹介します。バケツでも栽培できるようなので気になる方は是非やってみてください👍
画像/動画撮影はiphone11ですが、できるだけブレないように三脚・グリップで固定して使っています。関連機材を紹介します。
コメント