

Pythonを使ってセグメンテーションを実装していこうと思います。今回はセマンティックセグメンテーションで代表的なモデルであるU-Netを使っていきます。ラベル付け作業が予想以上に大変でして、画像枚数が少ないのでData Augmentationを活用していきます。
- 書籍が難しすぎて挫折した
- これからデータサイエンティストを目指したい
- 画像データのディープラーニングに興味がある
- 独自の画像データでディープラーニングをしたい
セグメンテーションとは❓という方は↓も併せてご覧ください。

今回は家庭菜園で撮影した画像をラベル付けしています。ラベル付け方法は↓で詳しく記載していますので併せてご覧ください。

マルチクラス分類の記事もつくりました。こちらはTensorFlow2.x系でどうしても実装したい!という方向けに変換コードも載せています↓。併せてご覧ください。

学習環境(PCスペック、Pythonライブラリ)
使用するPCスペックは↓です。セグメンテーションは画像を使ったディープラーニングなので、GPU搭載のPCをお勧めします。(もしくはGooogle Colab)
| 使用PCスペック | |
| OS | Windows 10 |
| CPU | AMD Ryzen 7 5800 |
| メモリ | 16 GB |
| GPU | GeForce RTX3070 |
GPUを使っていくので↓もインストールしていきます。CUDA toolkit関連のインストールはこのサイトに細かく掲載されています。
↓NVIDIA developerサイトよりダウンロード後インストールしてください。
- CUDA:11.3
- cuDNN:8.2
GPUが認識されているかは↓コードでチェックしてみてください。GPUとかグラフィックボードの名前(RTX****とか)が帰ってくればOKです。
python
from tensorflow.python.client import device_lib
device_lib.list_local_devices()次に、Pythonとライブラリは下記を準備していきます。
- Python : 3.7
- TensorFlow : 2.5.0
- Keras : 2.4.3
- matplotlib : 3.4.2
Anacondaで仮想環境を作り、そこへpip installすればOKです。やり方が不安な方はここを参照ください。これで多分動きますが、もしライブラリが不足していたら追加でインストールしてください。
U-Netの実装
- ソースコードの準備
ソースコードをgithubからクローンしていきます。今回は↓を使っていきます。クローンのやり方が分からない方はZipダウンロードでもOKです。ここを参考にしてください。デスクトップにunetディレクトリを置いておくと便利です。
- Data Setの準備
前の記事で苦労してつくったデータセットを準備していきます。↑で展開したunetディレクトリのdata→menmbrane→trainのなかにaug, image, labelディレクトリがあると思います。その中の画像をいったん全部消去して、image, labelディレクトリの中に、スナックエンドウの画像とラベル付けした画像をそれぞれ入れてください。augディレクトリは空っぽでOKです。
- JupyterNotebookの準備
U-Netモデルのコードを説明していきます。コードはAnacondaのJupyterNotebookで動作確認しています。unetディレクトリ直下にPython3のNotebookを作成してください。
- Data Augmentation
この状態から学習を開始することも可能ですが、今回は画像枚数が少数(30枚)なので先ずはData Augmentationを実施していこうと思います。↓のコードを入力して実行してください。
from data import *
data_gen_args = dict(rotation_range=0.2,#回転
width_shift_range=0.05,#水平移動
height_shift_range=0.05,#垂直移動
shear_range=0.05,#シアー変換
zoom_range=0.05,#ズーム
horizontal_flip=True,#左右反転
fill_mode='nearest')
myGenerator = trainGenerator(20,'data/membrane/train','image','label',
data_gen_args,save_to_dir = "data/membrane/train/aug")
num_batch = 3
for i,batch in enumerate(myGenerator):
if(i >= num_batch):
break
image_arr,mask_arr = geneTrainNpy("data/membrane/train/aug/","data/membrane/train/aug/")
実行すると先ほど空だったaugディレクトリへ画像が保存されます。簡単に説明するとオリジナル画像へ回転、水平移動、垂直移動などの処理を加え、水増ししています。↑コードの数値をいじると度合いを変化させられるので、興味ある方はやってみてください。
augディレクトリのデータセット(imageとラベル)をいくつかtestディレクトリへ移動させておくと後で検証用に使えるのでやっておきましょう。その時、imageデータを0.png, 1.pngといった具合にナンバリングするようにファイル名を変更しておいてください。
- model.pyファイルの書換え
いよいよ学習していくのですが、その前に一か所だけ修正してほしいところがあります。unetディレクトリに”model.py”ファイルが格納されていると思います。それをワードパットなどで開いてください。その中の↓コードを書き換えてください。書き換えたら上書き保存して閉じてください。
・オリジナルコード
model = Model(input = inputs, output = conv10)
↓
・書換えコード
model = Model(inputs, outputs = conv10) これはKerasのバージョンによって発生する問題で、オリジナルコードは旧バージョンのKerasコードです。Kerasのバージョンを下げる手法もありますが、GPUが使えなくなってしまうので、コードを書き換えてしまった方が無難です。
- 学習実行
↓のコードを入力して実行してください。batch_sizeとepochsはお好みの数値へ変えてOKです。OOM(Out of memory)を起こす場合はbatch_sizeを小さくすると良いです。セマンティックセグメンテーションはepochs数を多くとるのがコツだったりします。
from model import *
from data import *
model = unet()
model_checkpoint = ModelCheckpoint('unet_membrane.hdf5', monitor='loss',verbose=1, save_best_only=True)
imgs_train,imgs_mask_train = geneTrainNpy("data/membrane/train/aug/","data/membrane/train/aug/")
history = model.fit(imgs_train, imgs_mask_train, batch_size=8, epochs=1000, verbose=1,validation_split=0.2,
shuffle=True, callbacks=[model_checkpoint])実行すると学習がはじまるので、しばらく待ちましょう。
U-Netの学習結果
- 結果のプロット
学習が終了したら↓コードを実行してください。学習履歴をプロットできます。
import matplotlib.pyplot as plt
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
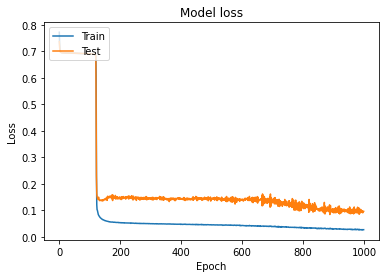
グラフが表示されたと思います。今回はこんな感じで学習できました。Test lossが十分下がりきらなかったので、画像枚数が少ないのが原因でしょうか。。。
- セマンティックセグメンテーション(AI)予測
では学習した重みデータを使って予測をしてみましょう。testディレクトリへ保存したimage画像からスナックエンドウの存在するエリアをAI予測していきます。↓のコードを入れて実行してください。
testGene = testGenerator("data/membrane/test")
model = unet()
model.load_weights("unet_membrane.hdf5")
results = model.predict_generator(testGene,2,verbose=1) #予測枚数に合わせ数値を変更してください。今回は2枚予測。
saveResult("data/membrane/test",results)実行するとtestディレクトリへ予測結果が出力されます。結果は↓の感じになりました。入力画像はData Augmentationしているので見づらいのはご容赦ください。
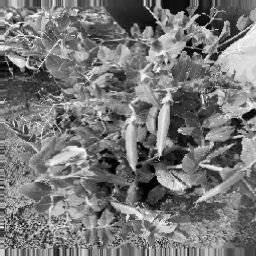





AI予測結果、ぼやけてます。でも薄っすら特徴は掴めていると思います。画像枚数を増やしていけばいい感じで学習できるのではないでしょうか?
今回はここまでとします。セマンティックセグメンテーションはCNN同様に転移学習、ファインチューニングができたり、エンコーダへ有名なCNNモデルを利用したり色々な工夫ができるのですが、それはまたの機会にします。
まとめ
- U-Netを使ってスナックエンドウの位置をセマンティックセグメンテーションしてみた。
- 入力画像をData Augmentationしデータ数を補った
- 30枚程度の画像だったが、薄っすら特徴を捉えることができた
コメント
大変わかりやすくて感動しました!!当方はMac userで、ブログどおりにJypyter Notebookを使ってコードを走らせると、学習、グラフ描出までできました。
が、いかんせんGPUを使っていないので、たったepoch 5でもマシンがアッチッチ、時間も数分かかり、「こりゃダメだ。Google Colabを使おう」と思い立ったのですが、gitHubからダウンロードしたソースコードを、Google Colabにて実装する方法がわからず途方に暮れています。。。
どうかこの迷える私をお助けください。。
かどさん
コメントありがとうございます。cpuマシンで画像関連の学習は厳しいですよね😂
ご質問の件、申し訳ありませんが、Colabでの実装をしたことが無いのでアドバイスができないというのが本音なのですが、、、
おそらくはColab上でGoogle Driveをマウントし、そこへGitHubコードをクローンすれば同じことができるかと思います。
お力になれずすみませんが、この辺りをググると同じようなことをやっている事例が見つかると思いますので挑戦してみてください👍
上手くいったら教えてもらえると嬉しいです😀
大変参考になりました ありがとうございます!
入力データをカラー画像で行いたいのですが、何かコードで変更すべき点はありますでしょうか?
コメントありがとうございます。
こちらの記事でカラー画像のセグメンテーションを実施しております。
ご参考にしてみて下さい。
https://farml1.com/multiclass_classification/