

Swin TransformerはMicrosoftが開発したTransformerをベースとしたモデルであり、様々なComputer VisionのBack boneとしてCNNのように汎用的に使える有能なモデルです。精度もばつぐんとのことなので試してみようと思います👍
Transformerを利用した画像分類モデルとして過去にViTを紹介しています。Swin Transformerのベースの考え方になるので良かったら併せてご覧ください。


Swin Transformerについて
Swin Transformerはいろいろなところで詳しく解説されています。私は論文と↓を参考にしました。


Swin TransformerはTransformerにおける画像認識における2つの問題点を改善したモデルになります。
- Patchを切り出して入力情報とするため、いろいろなサイズの画像から物体を認識することが難しい
- 画像の解像度が大きくなると計算コストがかかる
Swin Transformerはこれらを改善するために、Shift window(これがSwinの由来)を用い局所的なAttention計算を実施しています。またCNNのプーリングに似たような構造も取り入れ計算コストを下げる工夫がされています。
Swin Transformerを実装する
実装はAnacondaのJupyterNotebookを想定して記載します。必要あればインストールしてください。Anacondaって!?という方はここを参考にしてください。
今回はtimmを使った学習方法をご紹介します。timmはPyTorch Image Modelsライブラリで、いろいろなモデルとpre-trainedデータがそろっているライブラリです。数百種類のモデルを備えているので「最強の画像認識ライブラリ」とも言われています。
timmに備わっているSwin Transformerを使って学習していけば実装はすごく簡単です。
過去にもtimmでモデル実装しています。学習環境や、データセットは↓過去に実装したモノと同じですので、良かったら併せてご覧ください↓

学習を進めるにあたりData Augmentationは必須になってきます。Data AugmentationにはAlbumentationsを使っています。AlbumentationsによるData Augmentationは物凄く便利で、多彩な拡張が可能です。詳しくは↓過去の記事を参照してみてください。

以下にコード全文を記載します。
import glob
import os
import random
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
from tqdm.notebook import tqdm
from pathlib import Path
import timm
import albumentations as A
import time
import seaborn as sns
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
seed_everything(seed)
device = 'cuda'
# Training settings
epochs = 50
lr = 1e-6
gamma = 0.7
seed = 42独自のデータで実装する場合は↓のパスを任意に設定してください。画像データの保存方法についてもルールがあるので詳しくはここを参照してください。
train_dataset_dir = Path('./data/train')
val_dataset_dir = Path('./data/val')#Albumentationsの設定
#DataAugmationとしてResize(これはマスト), ShiftScaleRotate, RandomGamma,
#RandomBrightnessContrast, CoarseDropoutを実施
A_transforms = A.Compose([
A.Resize(224,224),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.2, rotate_limit=45, interpolation=1, border_mode=4, p=0.3),
A.RandomGamma(gamma_limit=(85, 150), p=0.3),
A.RandomBrightnessContrast(brightness_limit=0.5, contrast_limit=0.5, brightness_by_max=True, p=0.4),
A.CoarseDropout(max_holes=4, max_height=100, max_width=100, min_holes=1, min_height=50, min_width=50, fill_value=0, p=0.4)
])
def albumentations_transform(image, transform=A_transforms):
if transform:
image_np = np.array(image)
augmented = transform(image=image_np)
image = Image.fromarray(augmented['image'])
return image
data_transform = transforms.Compose([
transforms.Lambda(albumentations_transform),
transforms.ToTensor()
])
A_transforms_val = A.Compose([
A.Resize(224,224)
])
def albumentations_transform_val(image, transform=A_transforms_val):
if transform:
image_np = np.array(image)
augmented = transform(image=image_np)
image = Image.fromarray(augmented['image'])
return image
val_transforms = transforms.Compose([
transforms.Lambda(albumentations_transform_val),
transforms.ToTensor()
])
#Data set
train_data = datasets.ImageFolder(root=train_dataset_dir, transform=data_transform)
valid_data = datasets.ImageFolder(root=val_dataset_dir, transform=val_transforms)
#Data Loader
train_loader = DataLoader(dataset = train_data, batch_size=16, shuffle=True)
valid_loader = DataLoader(dataset = valid_data, batch_size=16, shuffle=True)ここでtimmでSwin Transformerを使うように設定します。
model = timm.create_model('swin_base_patch4_window7_224_in22k', pretrained=True, num_classes=3)
#pretrained=True :ファインチューニング学習します
#num_classes=3 :3クラス分類# Training
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
train_acc_list = []
val_acc_list = []
train_loss_list = []
val_loss_list = []
t1 = time.time()
model.to("cuda:0")
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
train_acc_list.append(epoch_accuracy)
val_acc_list.append(epoch_val_accuracy)
train_loss_list.append(epoch_loss)
val_loss_list.append(epoch_val_loss)
t2 = time.time()
#経過時間を表示
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}")# 結果の可視化
device2 = torch.device('cpu')
train_acc = []
train_loss = []
val_acc = []
val_loss = []
for i in range(epochs):
train_acc2 = train_acc_list[i].to(device2)
train_acc3 = train_acc2.clone().numpy()
train_acc.append(train_acc3)
train_loss2 = train_loss_list[i].to(device2)
train_loss3 = train_loss2.clone().detach().numpy()
train_loss.append(train_loss3)
val_acc2 = val_acc_list[i].to(device2)
val_acc3 = val_acc2.clone().numpy()
val_acc.append(val_acc3)
val_loss2 = val_loss_list[i].to(device2)
val_loss3 = val_loss2.clone().numpy()
val_loss.append(val_loss3)
sns.set()
num_epochs = epochs
fig = plt.subplots(figsize=(12, 4), dpi=80)
ax1 = plt.subplot(1,2,1)
ax1.plot(range(num_epochs), train_acc, c='b', label='train acc')
ax1.plot(range(num_epochs), val_acc, c='r', label='val acc')
ax1.set_xlabel('epoch', fontsize='12')
ax1.set_ylabel('accuracy', fontsize='12')
ax1.set_title('training and val acc', fontsize='14')
ax1.legend(fontsize='12')
ax2 = plt.subplot(1,2,2)
ax2.plot(range(num_epochs), train_loss, c='b', label='train loss')
ax2.plot(range(num_epochs), val_loss, c='r', label='val loss')
ax2.set_xlabel('epoch', fontsize='12')
ax2.set_ylabel('loss', fontsize='12')
ax2.set_title('training and val loss', fontsize='14')
ax2.legend(fontsize='12')
plt.show()学習結果
学習曲線は↓の感じになりました。
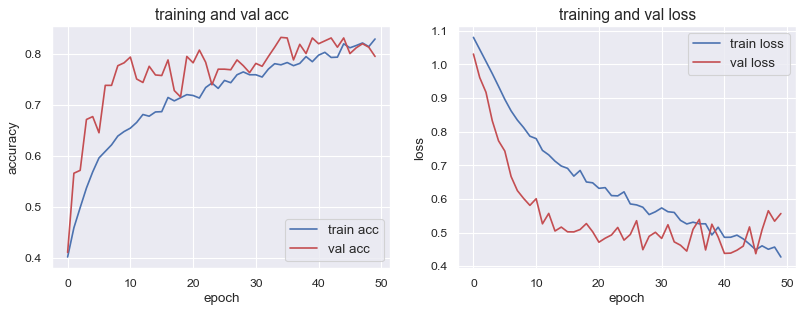
- Accuracy : 0.83
- Loss : 0.41
- Validation Accuracy : 0.85
- Validation Loss : 0.46
ViT, MLP-mixerとの比較
同じTransformerベースのモデルと比較してみます。
同じデータセット、Data Augmentationも同条件で比較した結果は↓です。ViTが最も良い結果となりました。Swin Transformerを使っておけば良いという簡単なモノでは無いようです😅
ハイパーパラメータの影響をかなり受けている感じもしますので、もう少しチューニングして比較する必要があるかもしれません。

学習速度の比較は↓です。MLP-MixerやViTに比べると時間はかかります。Shift windowを使うことで特徴量抽出するようなブロックが追加されていますので当然時間がかかる結果となっています。
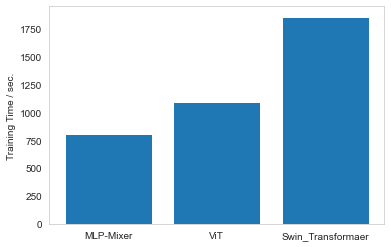
以上を踏まえるとSwin Transformerはいまいちでは?という結果になっています。ですがCNNのようにセグメンテーションや、物体検出などに使える柔軟性を考えると十分メリットあると思います。もう少しハイパーパラメータの調整で感覚掴む必要がありそうですが。。。
参考図書
この辺の書籍で勉強しています👍
コメント