

画像分類と言えば畳み込みニューラルネットワーク(CNN)が最もよく用いられている有名な手法だと思います。ですが、最近ではAttentionを基本構造に持つVision Transformer(ViT)のような畳み込み構造を用いない手法もよく見かけるようになってきています。今回は、そんな畳み込みやAttention構造を用いない手法として話題のMLP-Mixerをご紹介します。
MLP-Mixerは畳み込みや、Attentionを使わずに、MLP(多層パーセプトロン)を混ぜる(mixer)ことで画像分類のSoTAに匹敵する高精度モデルを構築できる手法です。また、並列に学習できることから学習が非常に高速とも言われている優秀なモデルです。
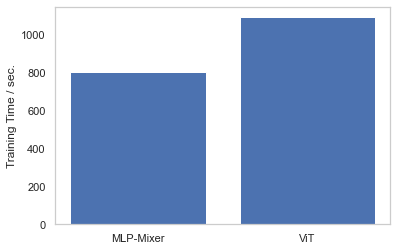
今回は独自のデータを使ってMLP-Mixerの実装と、ViTとの学習速度の比較を実施してみました。結果は↓となりだいぶ高速です!
それではMLP-Mixerの実装について説明していきます👍
CNN、ViTを用いた画像分類については、過去にまとめています。↓の記事も併せてご覧ください。
- ResNet


- EfficientNet


- ViT


MLP-Mixerについて
MLP-Mixerの構造はViTの構造とよく似ています。AttentionをMLP(多層パーセプトロン)に変えただけ、とも言えます。簡単に仕組みを説明します。詳しくは論文をご参照ください。
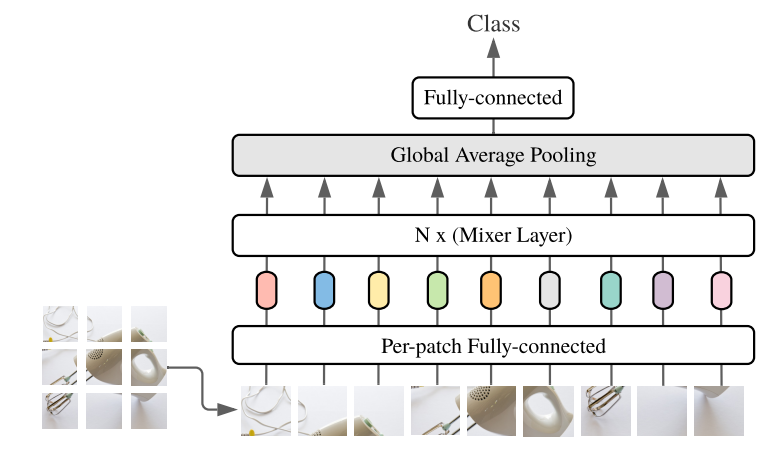
MLP-Mixerのブロック図からも、ViTの構造と似ていることが分かると思います。画像をPatchと呼ばれる小さい画像へ分割し、それぞれを入力とします。
まず、入力したPatch画像をPer-patch Fully-connected(全結合層)で特徴量化します。ここはシンプルな全結合層でそれぞれのPatchに対し特徴量を”Channel”という形で出力しています。
次にそれぞれのChannelを持ったPatchについて、MixerLayerを通します。MixerLayerの中身のブロック図は↓です。

MixerLayerの構造は2段階のMLP(多層パーセプトロン)になっています。
- まず入力データのPatchとChannelを転置して、それぞれのChannel毎にMLP学習します。
- 得られたChannel毎の結果をもう一度転置し、今度はPatch毎にMLP学習をします。
このようにしてMixerLayerで得られた出力を最後にGlobal Average poolingして分類する仕組みとなっています。
精度を上げるためにSkipp-connectionだったっり活性化関数 にGELUを使ったりしていますが詳細は論文を参照ください。
↓AI BitesさんのYoutubeが分かりやすいので参考に載せておきます。
学習環境
学習環境
ローカルGPU環境で実装していきます。MLP-Mixerの学習にはGPUがないとキツイです。CPU環境の方はGoogle Colabを利用することをお勧めします。
- OS : Windows 11
- CPU : AMD Ryzen7 5800
- メモリ : 16GB
- GPU : GeForce RTX3070 8GB
CUDAやライブラリ関連は過去の記事と同じ環境で実施していきます。ここを参照してください。
学習データセットの準備
独自画像データとしてお米のデータを使っていきます。

A:正常な籾 B:多少黒い斑点のある籾(食べれそう) C:黒い斑点が多い籾、緑色の籾(食べられなさそう、スカスカになってそう)
分類した画像は↓のようなフォルダの配置にそれぞれ保存します。ImageFolderという

データ数
- Train data A: 591
- Train data B: 670
- Train data C: 519
- Validation data A: 25
- Validation data B: 25
- Validation data C: 25
MLP-Mixerを実装する
実装はAnacondaのJupyterNotebookを想定して記載します。必要あればインストールしてください。Anacondaって!?という方はここを参考にしてください。
今回はtimmを使った学習方法をご紹介します。timmはPyTorch Image Modelsライブラリで、いろいろなモデルとpre-trainedデータがそろっているライブラリです。数百種類のモデルを備えているので「最強の画像認識ライブラリ」とも言われています。
timmに備わっているMLP-Mixerモデルを使って学習していけば実装はすごく簡単です。
過去に紹介したViTの実装と基本的には同じコードを使用します。Data AugmentationにはAlbumentationsを使っています。AlbumentationsによるData Augmentationは物凄く便利で、多彩な拡張が可能です。詳しくは↓過去の記事を参照してみてください。

MLP-Mixerの実行コードを↓に記載します。
import glob
import os
import random
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
from tqdm.notebook import tqdm
from pathlib import Path
import timm
import albumentations as A
import time
import seaborn as sns
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
seed_everything(seed)
device = 'cuda'# Training settings
epochs = 50
lr = 1e-6
gamma = 0.7
seed = 42AlbumentationsでのData Augmentationを設定していきます。
train_dataset_dir = Path('./data/train')
val_dataset_dir = Path('./data/val')
#Albumentationsの設定
#DataAugmationとしてResize(これはマスト), ShiftScaleRotate, RandomGamma,
#RandomBrightnessContrast, CoarseDropoutを実施
A_transforms = A.Compose([
A.Resize(224,224),
A.ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.2, rotate_limit=45, interpolation=1, border_mode=4, p=0.3),
A.RandomGamma(gamma_limit=(85, 150), p=0.3),
A.RandomBrightnessContrast(brightness_limit=0.5, contrast_limit=0.5, brightness_by_max=True, p=0.4),
A.CoarseDropout(max_holes=4, max_height=100, max_width=100, min_holes=1, min_height=50, min_width=50, fill_value=0, p=0.4)
])
def albumentations_transform(image, transform=A_transforms):
if transform:
image_np = np.array(image)
augmented = transform(image=image_np)
image = Image.fromarray(augmented['image'])
return image
data_transform = transforms.Compose([
transforms.Lambda(albumentations_transform),
transforms.ToTensor()
])
A_transforms_val = A.Compose([
A.Resize(224,224)
])
def albumentations_transform_val(image, transform=A_transforms_val):
if transform:
image_np = np.array(image)
augmented = transform(image=image_np)
image = Image.fromarray(augmented['image'])
return image
val_transforms = transforms.Compose([
transforms.Lambda(albumentations_transform_val),
transforms.ToTensor()
])
#Data set
train_data = datasets.ImageFolder(root=train_dataset_dir, transform=data_transform)
valid_data = datasets.ImageFolder(root=val_dataset_dir, transform=val_transforms)
#Data Loader
train_loader = DataLoader(dataset = train_data, batch_size=16, shuffle=True)
valid_loader = DataLoader(dataset = valid_data, batch_size=16, shuffle=True)timmでのPretraind modelとして”mixer_b16_224_miil_in21k”を選択。実行するとだ重みデータがダウンロードされます。モデルの設計はこれだけでOKです👍
model = timm.create_model('mixer_b16_224_miil_in21k', pretrained=True, num_classes=3)
#pretrained=True :ファインチューニング学習します
#num_classes=3 :3クラス分類# Training
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
train_acc_list = []
val_acc_list = []
train_loss_list = []
val_loss_list = []
t1 = time.time()
model.to("cuda:0")
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
train_acc_list.append(epoch_accuracy)
val_acc_list.append(epoch_val_accuracy)
train_loss_list.append(epoch_loss)
val_loss_list.append(epoch_val_loss)
t2 = time.time()
#経過時間を表示
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}")# 結果の可視化
device2 = torch.device('cpu')
train_acc = []
train_loss = []
val_acc = []
val_loss = []
for i in range(epochs):
train_acc2 = train_acc_list[i].to(device2)
train_acc3 = train_acc2.clone().numpy()
train_acc.append(train_acc3)
train_loss2 = train_loss_list[i].to(device2)
train_loss3 = train_loss2.clone().detach().numpy()
train_loss.append(train_loss3)
val_acc2 = val_acc_list[i].to(device2)
val_acc3 = val_acc2.clone().numpy()
val_acc.append(val_acc3)
val_loss2 = val_loss_list[i].to(device2)
val_loss3 = val_loss2.clone().numpy()
val_loss.append(val_loss3)
sns.set()
num_epochs = epochs
fig = plt.subplots(figsize=(12, 4), dpi=80)
ax1 = plt.subplot(1,2,1)
ax1.plot(range(num_epochs), train_acc, c='b', label='train acc')
ax1.plot(range(num_epochs), val_acc, c='r', label='val acc')
ax1.set_xlabel('epoch', fontsize='12')
ax1.set_ylabel('accuracy', fontsize='12')
ax1.set_title('training and val acc', fontsize='14')
ax1.legend(fontsize='12')
ax2 = plt.subplot(1,2,2)
ax2.plot(range(num_epochs), train_loss, c='b', label='train loss')
ax2.plot(range(num_epochs), val_loss, c='r', label='val loss')
ax2.set_xlabel('epoch', fontsize='12')
ax2.set_ylabel('loss', fontsize='12')
ax2.set_title('training and val loss', fontsize='14')
ax2.legend(fontsize='12')
plt.show()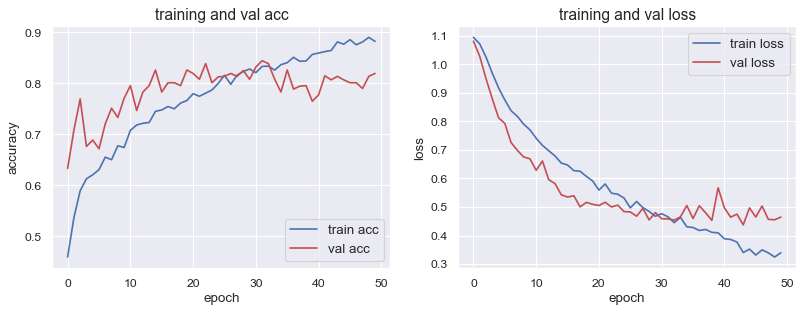
- Accuracy : 0.88
- Loss : 0.34
- Validation Accuracy : 0.82
- Validation Loss : 0.46
以上のコードでMLP-Mixerの学習ができると思います。皆さんも自分のデータで是非試してみてください👍
学習速度・精度の比較
今回実施したMLP-Mixerの学習と同じ条件下でViTの学習を実施しして比較してみました。学習速度については冒頭でも述べましたが、ViTより26%ほど高速でした。
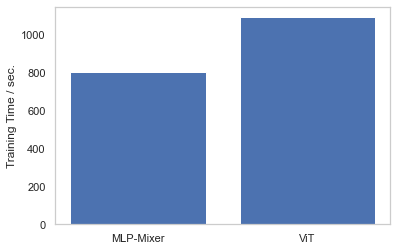
精度についてはViTにわずかですが劣る結果となりました。
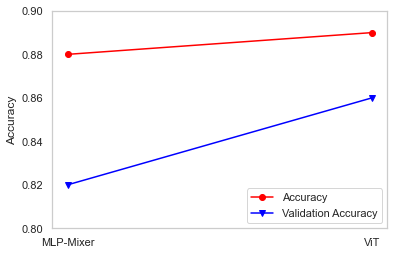
私が準備したデータセットではこのような結果となりました。準備したデータが少なかったためモデル精度の良し悪しを議論することはできないと思いますが、今回の条件下では「ViT」の方が高精度となりました。
学習時間は「MLP-Mixer」の方が圧倒的に早いという結果になり、一長一短の面白い結果になったかなと思います👍
コメント