

皆さんスナックエンドウって知っていますか?食べたことある人も多いと思います。皮まで食べられる枝豆みたいなやつ↓です。

突然ですが、この中に収穫できそうなスナックエンドウはいくつあると思いますか?実は4つくらいあるのですが、ぱっと見では全然わからないと思います…。スナックエンドウはおいしい反面、収穫がめっちゃ大変なんです。先日スナックエンドウの収穫をお手伝いしたのですが、あまりの面倒くささに早々にあきらめ、別のことを考えていました。
そうです!タイトル回収ですが、スナックエンドウを物体検出して収穫を楽にしたい!というのが今回のモチベーションになります。
- AI・機械学習を勉強したいけど、何からやればよいか分からない
- 書籍が難しすぎて挫折した
- これからデータサイエンティストを目指したい
- 物体検出が楽しそう
著者がポイントとして考える、AIの基礎をできるだけ簡単な形でお伝えします。書籍等で勉強する前にご一読いただけると、理解を深めることができると思います!pythonの簡単なコードを併せて説明していきます。
物体検出とは?YOLOとは?
物体検出とは画像(映像)から物体の位置と種類を検出するAIモデルのことです。物体検出モデルを使うことで↓のようなことができます。

AI・機械学習初心者の方でも見たことあると思います。こんな感じのことが実は割と簡単にやれてしまうのです!結構興奮しますよね?私だけ?
今回は物体検出のアルゴリズムとしてYOLOv3を実装していこうと思います。YOLOはYou Look Only Once(見るのは一度きり)の頭文字をとったモノでYou only live once=(人生一度きり)のスラングのようですw、その名の通り一度ディープラーニング(畳み込みニューラルネットワーク:CNN)を一回通すことで物体検出できてしまうというモノです。YOLOは上図のように物体の位置を”バウンディングボックス”という枠で示し、さらに種類もわかり、それでいて高速という最高にヤバイAIです。ちなみに自動運転や、自動車メーカの製造ラインでもYOLOのシステム導入・PoCは数多く実施されています!そのくらい凄いやつということです。
YOLOのアルゴリズムについて、詳細はここでは省略します。詳しく知りたい方はググってみてください(丸投げ)。ここでは、とりあえず使ってみる!ことに重点を置きます。
YOLOv3モデル作成ステップ
さて、いよいよ物体検出モデルをつくっていきますが、その前に今回使用PCのスペックを確認しておきます。今回は普通のスペックのPCでモデル作成していきます!
| 使用PC | |
|---|---|
| OS | Windows 10 |
| CPU | Core i5 |
| メモリ | 8 GB |
| GPU | オンボード |
ディープラーニングしていくのでGPU搭載していた方がいいのですが、今回は数十枚の画像で実施していくのでGPUなしで気長にやっていくこととします。画像枚数が多い方はGPU搭載PCもしくはGoogle Colaboratory※なんかで挑戦されると良いと思います。※Google Colaboratory:Google社が無料で提供している機械学習の教育や研究用の開発環境
YOLOv3のモデルは次のステップでつくっていきます。
- Anacondaのインストール
- YOLOv3の仮想環境をつくる
- 必要なライブラリを追加する
- YOLOv3のソースコードを準備
- ディープラーニング(以下:学習)済みモデルでの動作確認
- スナックエンドウの画像へアノテーション(タグ付け)処理
- 学習前のあれこれ準備
- YOLOv3の学習実行
- 結果確認!
長くなりそうなので、今回は”学習済みモデルでの動作確認”まで実施しようと思います。
Anacondaのインストール
ディープラーニングは適切な環境設定が重要なのですが、それを簡単に実行できるのがAnacondaです。これさえ入れておけばPythonプログラミングで困ることはほとんど無くなると思います。Anacondaスゲェーっす。
https://www.anaconda.com/
↑サイトからそれぞれの環境にあったAnacondaをダウンロードしてください。
GetStarted → Down Load Anaconda Installers → windows python3.8 64-Bit Graphical Installer (2021年5月の時点)
ダウンロードが完了したら、exeファイルを起動しインストールを実行してください。
YOLOv3の仮想環境をつくる
Anacondaを使って仮想環境をつくっていきます。スタートメニューから”Anaconda3”→”AnacondaPrompt”を起動してください。
こんな感じのが出てきたと思います。ここへ以下のコードをコピペしてください。
conda create -n yolo_v3Proceed ([y]/n)?と出てきたら”y”を入力しエンターを押せばOKです。
これはAnaconda上に箱をつくる感覚で、この箱の中にYOLOv3を起動するための様々なツールを入れていきます。
次につくった仮想環境(箱)をアクティベートしましょう。以下コードを入力しエンターを押してください。
conda activate yolo_v3(base)→(yolo_v3)へ変わったと思います。これでアクティベートは完了です。この状態でAnaconda Promptを一旦そのままにしておいてください。後で使います!
必要なライブラリを追加する
とりあえずYOLOを動かしていくため以下のライブラリをインストールしていきます。ライブラリとはスマホでいうアプリみたいなもので、ある目的を達成するために必要なアプリを入れるような感覚です。
- Tensorflow
- Keras
- Matplotlib
- Pillow
- h5py :2.10.0
2021/10/22追記:Kerasをインストールする再にh5pyが同時にインストールされますが、h5pyのバージョン指定が必要とのご指摘ありました。↓のコードで先ずh5pyをインストールしてください。
pip install h5py==2.10.0以上のライブラリをインストールしていきますが、ここでこれらのバージョンが重要になってきます。YOLOだけでなく機械学習全般に言えることですが、ライブラリのバージョンが合わなくて動作しない問題はあるあるです。気を付けましょう。以下のコードをコピペしてエンターを押してください。
conda install tensorflow==1.14.0 keras==2.2.4 pillow matplotlibインストールは時間がかかるので気長に待ちましょう。”Tensorflow 1.14.0″と”Keras 2.2.4″を入れましょう(上記コードをコピペしていればOKです)。最新バージョンでは動きませんのでご注意を。
YOLOv3のソースコードを準備
コードをいちから書くのは無理ですよね。大丈夫です。YOLOはオープンソースになっていますのでそれを活用させていただきましょう。
以下のサイトへアクセスしてkeras-yolo3-master.zipをダウンロードしましょう。ダウンロードしたら解凍してデスクトップへ置いてください。
https://github.com/qqwweee/keras-yolo3
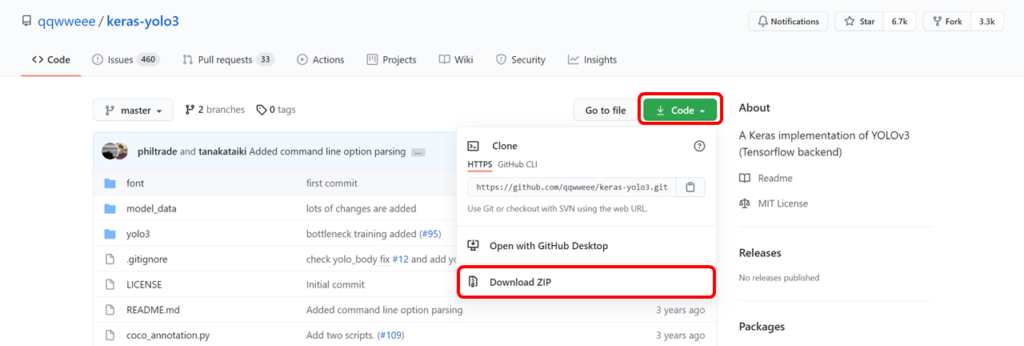
Gitを使えるかたはgit cloneコマンドでやってももちろんOKです。
学習済みモデルでの動作確認
以前の記事で、ディープラーニング学習するということは、何らかの構造式ができるということを説明しました。ここでは過去に学習した構造式(モデル)のウェイトを使ってYOLOv3の動作確認していこうと思います。
過去に学習済みのモデルを、以下の URL からダウンロードしてください。
https://pjreddie.com/media/files/yolov3.weights
ダウンロードしたファイルは、先ほどデスクトップに解凍したkeras-yolo3-masterフォルダへ保存してください。
ここで、先ほど一旦置いてあったAnaconda Promptへ戻りましょう。以下のコードを入力しディレクトリへ移動します。以下のコードをコピペして実行してください。
cd Desktop\keras-yolo3-master次に学習済みモデルを使うため、あれこれやります。理解できなくても大丈夫です。
ダウンロードしたweightをkerasで使えるようにコンバートしていきます。以下のコードを入力し実行してください。
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5model_dataディレクトリにyolo.h5という学習モデルをつくりました。yolo.h5が保存されていればOKです。
さて、ここでいよいよ物体検出をやっていきましょう。みなさん適当な画像をご用意ください。私は↓のような画像を用意しました。人、車、犬、猫などが写っていると分かりやすいです。

画像を用意したら、keras-yolo3-masterフォルダへ入れてください。ちなみに画像の名前は”traffic.jpg”としておきます。
画像が用意できたら、Anaconda Promptへ下記コードを入れてYOLOv3を起動しましょう!
python yolo_video.py --imageこのコードを入れるとtensor flowが動き出しますので、しばらくお待ちください。
しばらくするとInput image filename:と出てくるので、先ほど用意した画像の名前を入力します。
私の場合は画像の名前を”traffic.jpg”としたので下記になります。
Input image filename:traffic.jpgこのコードを実行するとYOLOv3による物体検出がおこなわれます。結果は↓になります。
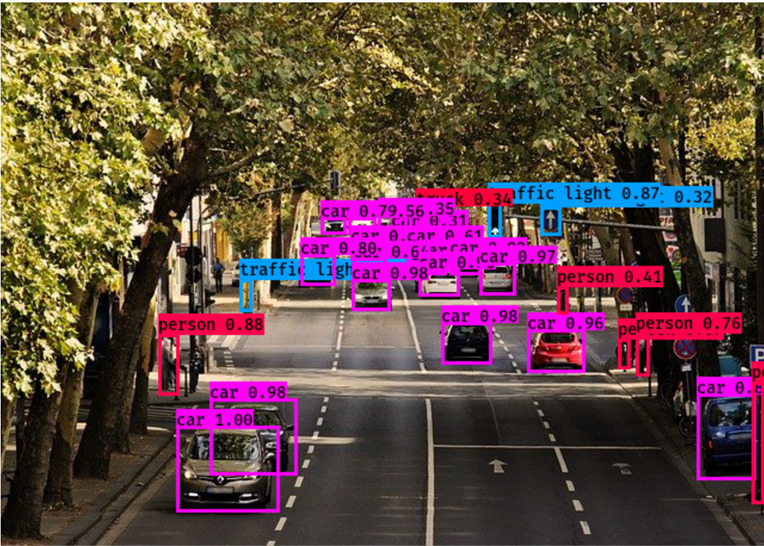
ここまで頑張っていただいたあなた!かなり感動したと思います。人の目でもよーく見ないと分からないモノも認識していますね。これをわずか数秒で出力できたと思います。物体検出の技術はすごいですね~。
これで無事に動作確認を完了ということになります。結構面白いので色々な画像で試してみることをおすすめします。また、動画ファイルをお持ちの方は動画でも試すことができます。以下のコードを入力し、***のところへファイル名を記入して実行するとOKです。色々とお試しあれ。
python yolo_video.py --input ***.mp4まとめ
今回はYOLOv3アルゴリズムを使って学習済みモデルでの動作確認まで実施しました。次回はいよいよスナックエンドウの画像を実際にYOLOv3へ学習させ、物体検出していこうと思います。
お楽しみに!

コメント
こんにちは!
記事を参考にさせていただきました、ありがとうございます。
動作確認の後、Input image filename:が再度出るのですが、動作確認を終了させる方法はありますか?
また、kerasをインストールする前にh5pyのライブラリをバージョン2.10.0などと指定してインストールする必要があるようです。
kerasをインストールするとh5pyの最新バージョンをインストールしてしまい、その影響でエラーが出ました。
参考:https://qiita.com/Hiroki-Fujimoto/items/b078bfb680fb710c38c1
こちらは他の方の参考になればと思い、コメントさせていただきます。
コメントありがとうございます。
Input image filename:が再度出るのですが、動作確認を終了させる方法はありますか?
とのご質問ですが、「CTRL+C」でタスクを終了させることができます。試してみてください。
kerasをインストールするとh5pyの最新バージョンをインストールしてしまいその影響でエラーが出ました。
ご指摘ありがとうございます。h5pyは2.10.0で動作を確認しております。
最新バージョンがインストールされている場合はお手数ですがアンインストール後、バージョン2.10.0を指定して再インストールしてください。
pip uninstall h5py
pip install h5py==2.10.0
本文にも追記しておきます。ありがとうございました。
こんばんは、初心者の質問で申し訳ないです。
自分はpython3.9なのですが、Tensorflow Kerasのバージョンは上記の記事で大丈夫ですか?
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5の所まで行くと、
ModuleNotFoundError: No module named ‘keras’というエラーがでます
tikuさん
コメントありがとうございます。エラーの内容からいくとkerasが上手くインストールされていないようです。
pip listと入力してkerasがインストールされているか確認してみてください。
インストールされていなければ pip install keras==2.2.4 でインストールしてください。
もしインストールされていれば、一旦pip uninstall kerasでアンインストールした後、もう一度インストールしてみてください。
また、Python3.6で動作を確認しています。もし上手くいかなければ、こちらも変更して試してみてください。
上手くいくことを願っています👍