

スナックエンドウの収穫がしんどいので物体検出で楽にしようというモチベーションで実施しています。前回は、YOLOv3の学習済みモデルでの動作確認まで実施しました。詳細は↓を見てください。

今回は、スナックエンドウの画像を実際にYOLOv3へ学習させ、物体検出していこうと思います。
- Anacondaのインストール
- YOLOv3の仮想環境をつくる
- 必要なライブラリを追加する
- YOLOv3のソースコードを準備
- ディープラーニング(以下:学習)済みモデルでの動作確認
- スナックエンドウの画像へアノテーション(タグ付け)処理 👈ここから
- 学習前のあれこれ準備
- YOLOv3の学習実行
- 結果確認!
スナックエンドウの画像へアノテーション(タグ付け)処理
撮影した画像のアノテーションから始めます。アノテーションとは、画像データのどこにスナックエンドウがあるか、正解のタグ付けを実施することです。画像と正解タグのセットを教師データといいます。
さて、やっていきましょう!まずは画像のサイズを調整していきます。今回はiphoneで撮影した画像を使いましたが、そのままでは扱いにくいので、320×427pixelへリサイズしました。
アノテーションには”labelimg”というソフトを使用します。↓へアクセスし、それぞれの環境にあったモノをダウンロードしてください。
https://tzutalin.github.io/labelImg/
ダウンロードしたらデスクトップへ解凍してください。exeファイルを実行すると↓のようなウィンドウが出てくると思います。
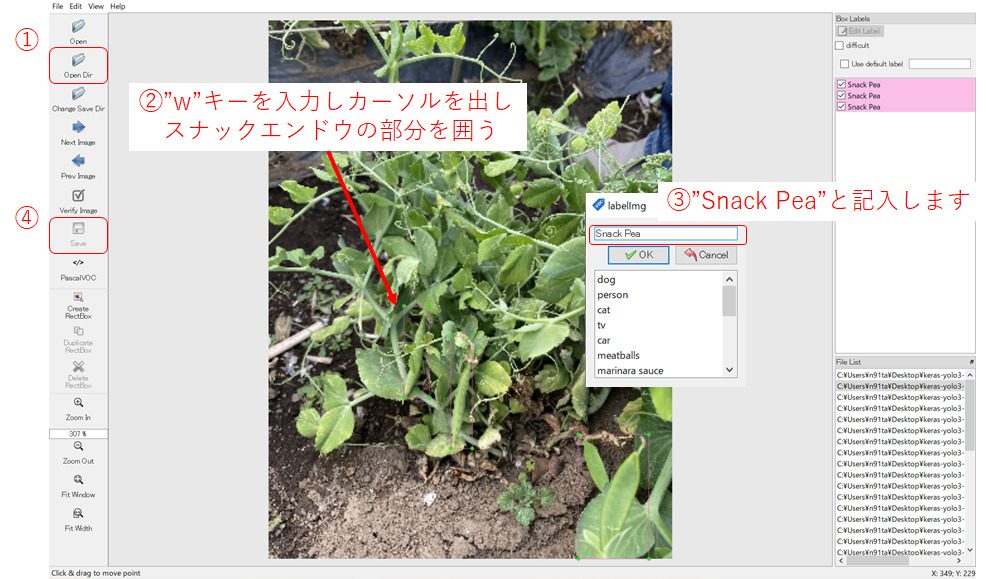
手順は4つです。①で画像を保存したディレクトリを開きます。②画像上で”w”キーを押しスナックエンドウの画像をバウンディングボックスで囲ってください。③ラベリング名を”Snack Pea”としておきます。④すべてのスナックエンドウの画像を囲えたら保存します。ファイル名は必ず画像と同じ名前.xmlにしてください。
以上の手順を全ての画像で実施してください。ちなみに今回は36枚の画像を用いています。
学習前のあれこれ準備
ここからは学習するために必要な処理を実施していきます。手順を説明しますのでそれ通りやっていただければOKです。その1~4まであります。
~その1 ファイル保存編~
まずは、新しいフォルダを作成し、アノテーションしたファイルと元画像を移動してください。フォルダ名、場所は↓の画像の通りにお願いします。フォルダ名を間違えないようにしてください→”VOCdevkit” , “VOC2007” , “Annotations” , “ImageSets” , “JPEGImages”。間違えるとエラーになります。
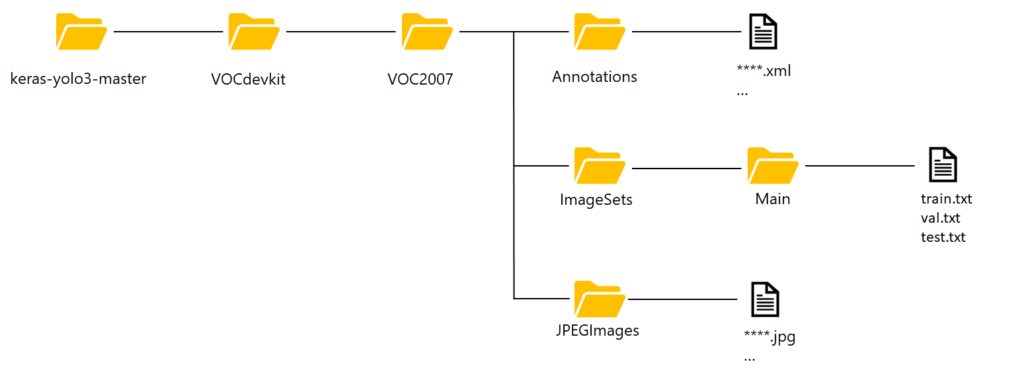
画像とアノテーションファイルを移動しましたら、次にImageSet→Main→へ入れるテキストファイルを説明します。↓の感じで、画像の名前から拡張子”.jpg”を抜いたモノを列挙してください。train.txt、val.txt、test.txtはそれぞれ、学習に用いるファイル、検証用に用いるファイル、学習に用いないテスト用のファイルとなっています。YOLOv3を実行すると、自動で学習データを分割し、クロスバリデーションしてくれるようなので、val.txtは空にします。test.txtに効果を確認するためいくつかファイルを登録しておきましょう。残りはtrain.txtへファイル名を登録してください。ここで注意ですが、最終行も改行が必要です!
まとめると↓のようなイメージになります。
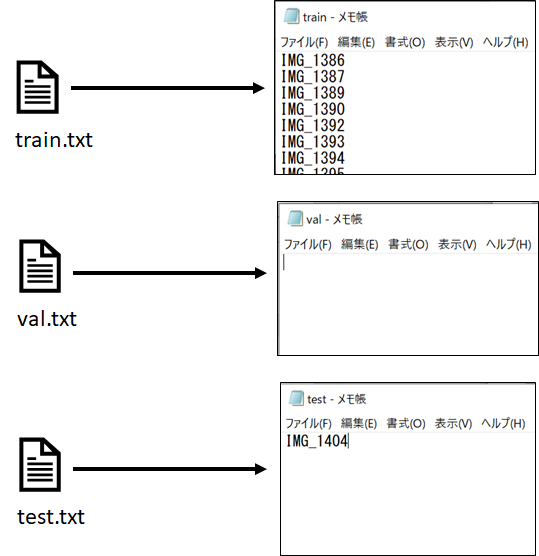
各テキストファイルをMainフォルダへ入れたらOKです。
~その2 アノテーションファイル生成編~
keras-yolo3-masterフォルダ下にあるvocannotation.pyをワードパットなどで開いてください。6行目を↓のように書き換えてください。
classes = ["Snack Pea"]書き換えたら保存して閉じてOKです。
次にアノテーションファイルを生成していくのですが、前の記事で作成したYOLOv3実行環境をアクティベートしましょう。AnacondaPromptを開きアクティベート後、作業ディレクトリへ移動してください。↓のコードを実行すればOKです。
conda activate yolo_v3
cd Desktop\keras-yolo3-master準備が整いましたら↓コードを実行してアノテーションファイルを生成します。
python voc_annotation.pyすると、keras-yolo3-masterフォルダ下に下記3つのテキストファイルが生成されればOKです。
- 2007_train.txt
- 2007_val.txt
- 2007_test.txt
後で使うのでAnacondaPromptはそのまま置いといてください。
~その3 コードの書換え編~
- voc_classes.txtの書換え → my_classes.txtとして保存
keras-yolo3-master/model_data下にあるvoc_classes.txtの中身を書換えます。開いてもらうと”aeroplane”、”bicycle”…と色々書いてあると思いますが全部削除し、
Snack Pea
を記入し、ファイル名は”my_classes.txt“で名前をつけて保存してください。
- train.pyの書換え
keras-yolo3-masterフォルダ下にあるtrain.pyをワードパットなどで開いてください。18行目を↓のように書換えてください。
annotation_path = ‘2007_train.txt’
さらに20行目を↓のように書換えてください。
classes_path = ‘model_data/my_classes.txt’
さらにbatch_sizeを変更していきます。今回はノートPCを使用するのでメモリが足らないため”batch_size=8″に変更します。58行目あたり、81行目あたり(2か所あります)を↓のように書換えてください。
batch_size = 8
以上を書換えましたら、上書き保存して閉じてください。
~その4 weightのコンバート編~
長くなってすみませんもう少しです。↓のコードをAnacondaPromptで実行してください。
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5お疲れ様でした。これで準備完了です!
YOLOv3の学習実行
- 学習!
いよいよスナックエンドウの画像を学習させます。↓のコードを実行してください。注意:学習に数時間かかる場合があるので、時間があるときに実行してください。
python train.py実行すると何やら文字がババーっと出てくると思いますが、完了するのをひたすら待ってください。
trained_weights_final.h5上記コードがAnacondaPromptに現れ、keras-yolo3-master/logs/000/下にファイルが生成されれば完了です。これがスナックエンドウの学習モデルとなります。AnacondaPromptはまだそのまま置いといてください。
- うまく学習できたか確認
tensorboardを利用して学習の進行状況を確認できます。“新たに”AnacondaPromptを開いて↓コードを実行してください。
conda activate yolo_v3
cd Desktop\keras-yolo3-master
tensorboard --logdir logs実行後、下記URLにアクセスするとグラフを確認することができます
http://localhost:6006/
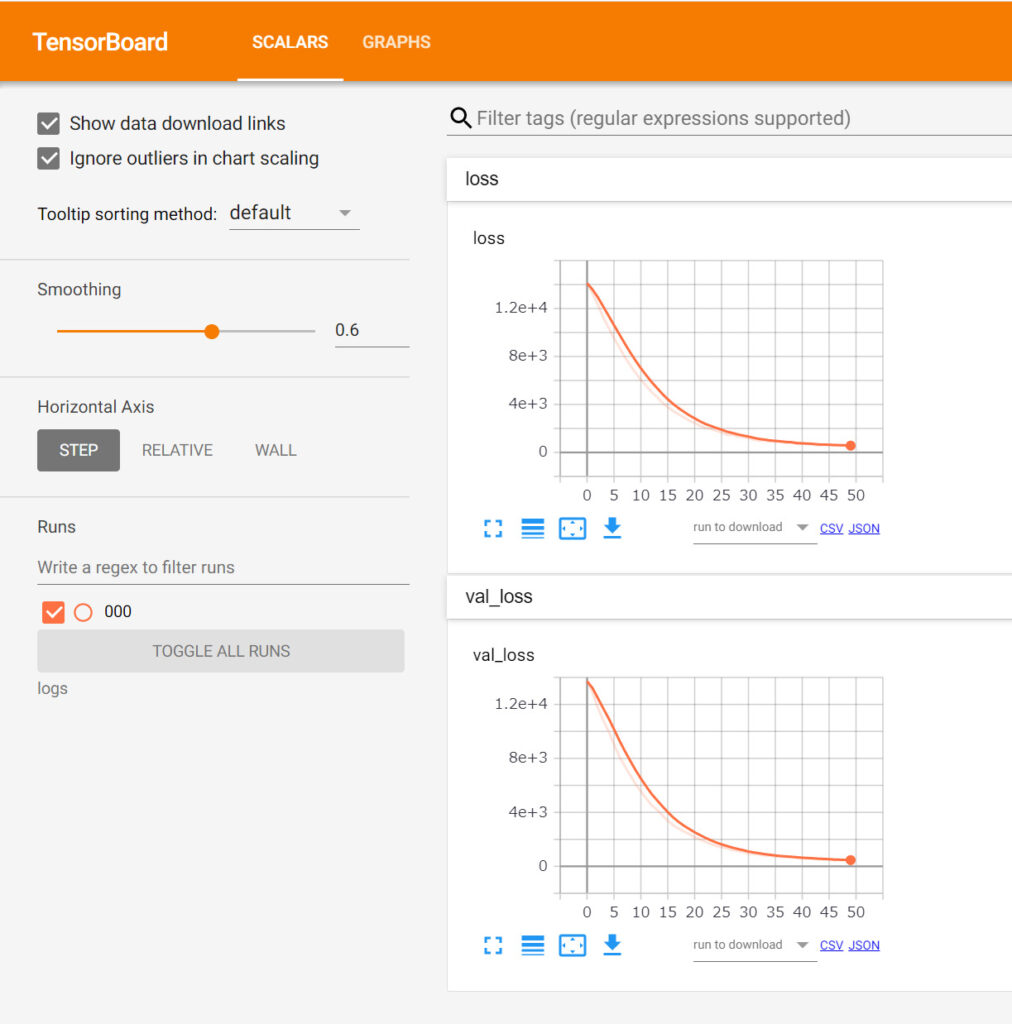
こんなグラフが出てきます。簡単に説明すると、グラフの横軸は学習エポック(繰り返し)数、縦軸はロス(正解と予測の乖離)となっていっます。うまく学習が進んでいると、学習エポックが進むに連れ、ロスが小さくなってくるのが確認できると思います。また、上のグラフは学習に使用したデータを使ったロスを示していますが、下のグラフは検証用データを使ったロスを示しています。下のグラフのロスが上昇してくると、”過学習”という機械学習でよくある汎用性を落とす問題となります。今回の場合、それも見られずGOODだと思います。
結果確認!
さて、いよいよスナックエンドウの画像を見分けられるか、学習したモデルをつかって挑戦してみようと思います。上で学習したモデルを読み込めるように少しだけ書換えをしましょう。
- yolo.pyの書換え
keras-yolo3-masterフォルダ下にあるyolo.pyをワードパットなどで開いてください。23行目を↓のように書換えてください。
“model_path”: ‘logs/000/trained_weights_final.h5’,
さらに25行目を↓のように書換えてください。
“classes_path”: ‘model_data/my_classes.txt’,
書換えが完了したら上書き保存してください。これで準備OKです。
AnacondaPromptへ下のコードを入力してください。
python yolo_video.py --image実行すると、ババーっと文字が出てきて、最後に”Input image filename:”が表示されると思います。ここへ、学習へ使用していないスナックエンドウ画像の名前を入れます。拡張子まで精確に入れてください。
Input image filename:*****.jpg
こんな感じで物体検出できました!左がYOLOv3の推論結果、右が正解のラベルになります。
バウンディングボックスの位置は問題なさそうです。ちなみに0.85というのは確率値です。
画像からまだ3個検出できていないスナックエンドウもあります。精度を上げていくためには、まずは学習させる画像の枚数を増やしていくことですが、train.pyの中のハイパーパラメータを変更することでも変わってきます。その辺りはいろいろ試していただき、体感してもらうと良いと思います。
さいごに
長くなってしまいましたが、無事にスナックエンドウの画像を物体検出することができました。YOLOは機械学習初心者のかたでも比較的簡単に実行できるプログラムとなっています。是非ご自身の身の回りで実践してみてください。AI・機械学習の面白さが分かると思います!
コメント