

Pix2PixはGAN(Generative Adversarial Network)を使ったアルゴリズムの一つで、画像(入力)から画像(出力)を生成する仕組みになっています。ペアの画像を用意し入力画像の特徴量を基に、出力画像を生成することになります。これを利用してモザイク状の画像を入力してアニメ顔を出力するモデルをつくってみます。
Pix2Pixモデルは過去の記事で記載したモノと同じ方法でつくっていきます。環境設定やマシンスペックの詳細は↓をご覧ください。

ソースコードは↓のGitHubを用いています。git cloneもしくはデスクトップ等へダウンロード→展開してください。
データセットの準備
アニメ顔のデータセットは↓をつかわせてもらいました。

この画像に入力画像のペアをつくっていきます。イメージは↓の感じで入出力画像を横に並べたモノをつくります。今回は右側を入力、左側を出力画像としました。

ダウンロードした画像に対し画像変換することでデータセットをつくっていきます。ダウンロードした画像はdatasetディレクトリ下へanimeディレクトリ、その直下へtrainディレクトリをつくりそこへ保存してください。
/datasets
-> anime #これ以下のディレクトリを作成してください
->test
->train
img00000000.png
img00000001.png
img00000002.png
img00000003.png
....
->valダウンロードした画像を10,000枚つかいました。全部使うと学習時間が大分かかります・・・
画像の準備ができたらJupyterNotebookで↓のコードを実行してください。
import glob
from PIL import Image
import cv2
import numpy as np
anime_faces = glob.glob("./datasets/anime/train/*.png") #ダウンロードした場所を指定してください。
for path in anime_faces:
with Image.open(path) as img:
orig = img.resize((256, 256), Image.LANCZOS)
mosaic = orig.resize((4, 4), Image.NEAREST) # オリジナルデータを4×4のモザイク画像へ変換します
mosaic = mosaic.resize((256, 256), Image.NEAREST)
orig = np.array(orig)
mosaic = np.array(mosaic)
data = cv2.hconcat([orig, mosaic])
img_RGB = cv2.cvtColor(data, cv2.COLOR_BGR2RGB)
cv2.imwrite(path, img_RGB)実行するとtrainディレクトリへ保存した画像が変換されていると思います。
trainディレクトリから適当に画像を選んでvalディレクトリとtestディレクトリへ入れてください。
- train : 6,900枚
- val : 3,000枚
- test : 100枚
これでデータセットの準備は完了です。
Pix2Pixモデル学習
学習の手順は過去の記事と同じです。AnacondaPromptやWindowsPowerShellで学習を実行していきます。
↓のコードを実行すると学習開始します。※時間がかなりかかりますのでご注意ください。
python train.py --dataroot ./datasets/anime --name anime_pix2pix --model pix2pix --direction BtoA --display_id 0 --n_epochs_decay 200 --batch_size 32 --netD n_layers実はいろいろ試して引数を追加しています。簡単に説明しますと↓の感じです。
- –dataroot : 画像保存場所
- –name : 学習モデルの名称
- –model : アルゴリズムの選択(今回はPix2Pix)
- –direction : 入力データと出力データの方向(今回は右側が入力、左側が出力のBtoA)
- –display_id : PyTorchの学習中データの可視化(今回は可視化しないため0)
- –n_epochs_decay:エポック数に対し学習率を下げる設定(今回は200epochsで学習率0になるように設定)
- –batch_size:バッチサイズ
- –netD:Discriminatorで層を指定するように変更
詳細はoptionsディレクトリのtrain_options.py とbase_options.pyに記載されていますのでご覧いただくと良いかと思います。
初期設定の学習率0.0002で100epochs、学習率を減衰させ200epochsの計300epochs学習させた結果を↓に示します。
Pix2Pix画像生成
入力画像
出力画像







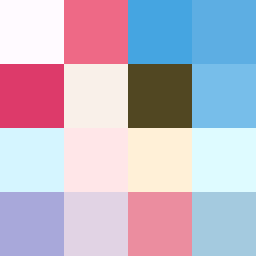

崩れてはいますが、アニメ顔の生成はできているようです。出力画像と比べると生成画像は似ていないモノですが、これはAIがいい感じで生成した顔画像なので今回の使い方であれば特に気にしなくてよいと思います。顔のパーツはある程度生成できるようですが、帽子や服といったパーツの生成は難しいようですね。。。
なかなか難しいですが(これでも学習でいろいろ調整したんですが・・・)、一応モデルができましたので、これを使って自前のモザイク画像でアニメ顔を生成してみます。
Pix2Pixモデルでオリジナルアニメ顔を生成してみる
オリジナルの4×4のモザイク画像をつくるのですが、
- 適当につくったモザイク画像でも生成できる
- 同じようなモザイクパターンを使えば同じようなアニメ顔を生成できるのか
この辺りを実験してみようと思います。
画像生成については↓のコードを実行することでresultsディレクトリ下へ画像が生成されます。独自の入力画像を使う場合は./datasets/anime/testディレクトリへ画像を入れてください。
python test.py --dataroot ./datasets/anime --name anime_pix2pix --model pix2pix --direction BtoAまず、何となく顔っぽい感じでモザイク画像をつくった場合と単色(黒)を入力画像としてアニメ顔を生成してみます。
入力画像
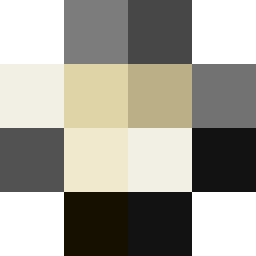
↓

↓
出力画像


顔っぽっいモザイク画像をからは一応アニメ顔っぽい画像が生成されましたが、単色では崩れた画像になりました。やはり学習させてないパターンに対しては対応できないようです。
次に同じモザイクをベースにして、色相を変えた場合を試してみました。
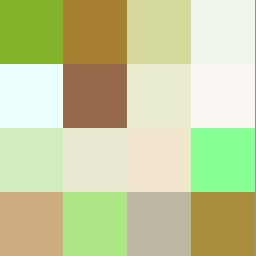
↓

↓
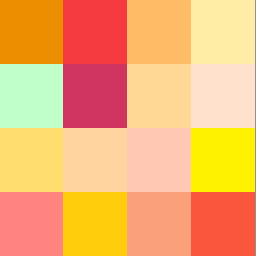
↓



生成画像を比較すると色味は表現できているけれども、生成される顔画像はあまり似ていないのでは?と思いました。今回のモデルで好みのアニメ顔を生成するようにコントロールすることは難しそうです。
Pix2Pixでいろいろ遊んでみました。本当はもう少し鮮明なアニメ顔を生成したかったのですが、この辺が限界でした。。。お時間ある方は面白いので試してみてください。
コメント