

Vision Transformer(通称:ViT)は画像認識モデルですが畳み込みを実施しません。ViTは画像認識の分野で革命的な技術と言われており、CNNを凌ぐ性能を持つ!とも言われています。
今回は独自のデータを使ってViTモデルをつくってみようと思います👍
- PyTorchでの独自データの分類
- ViTのファインチューニング学習
- Data Augmentation
- CNNとの比較
この辺りをやってみます。ViTはファインチューニングすることで本来の性能を引き出せるのですが、過学習しやすい傾向があるようなのでData Augmentationも試してみます。
ViTの説明・実装は過去の記事↓をご覧ください。

学習環境
過去の記事と同じ環境で実施していきます。ここを参照してください。学習はGPU環境での実施を推奨します。
コード
コードはViTをPyTorchで実装したvit-pytorchを使わせてもらいました。

コードのダウンロードもしくはgit cloneして作業フォルダをつくってください。分からない方はここを参考にしてください。
独自のデータセットを準備する
今回は独自のデータとして過去の記事でつくったお米のデータを使っていきます。
A:正常な籾
B:多少黒い斑点のある籾(食べれそう)
C:黒い斑点が多い籾、緑色の籾(食べられなさそう、スカスカになってそう)
分類した画像は↓のようなフォルダの配置にそれぞれ保存してください。

trainには学習用データセット、valには検証用のデータセットを入れてください。このように分けておくと簡単に学習できますので、やっておきましょう!
ちなみにここで使ったデータセットは過去にEfficientNetを実装するときに使ったモノです↓


独自のデータセットでViTファインチューニング学習
実装はAnacondaのJupyterNotebookを想定して記載します。必要あればインストールしてください。Anacondaって!?という方はここを参考にしてください。
コードは作業フォルダのexamples→cats_and_dogs.ipynbをベースに独自データで学習できるようにアレンジしていきます。
ライブラリのインポート
ライブラリをインポートしていきます。ここでエラーがでた場合はpip install ***で必要なライブラリをインストールしてください。
from __future__ import print_function
import glob
import os
import random
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from PIL import Image
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
from tqdm.notebook import tqdm
from vit_pytorch.efficient import ViT
from pathlib import Path
import seaborn as sns
import timm
from pprint import pprint学習条件の設定をしていきます。条件を変更したい場合はここの数値を変更してください。
# Training settings
epochs = 50
lr = 3e-5
gamma = 0.7
seed = 42シードの設定をしていきます。ここはデフォルトのままでいきます。
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
seed_everything(seed)cudaを使用して学習していきます。
device = 'cuda'学習データセットの設定
データセットの保存してあるパスを指定します。
train_dataset_dir = Path('./data/train')
val_dataset_dir = Path('./data/val')データセットの中身を確認します。データセットがうまく読み込めているか確認してください。
files = glob.glob('./data/*/*/*.jpg')
random_idx = np.random.randint(1, len(files), size=9)
fig, axes = plt.subplots(3, 3, figsize=(8, 6))
for idx, ax in enumerate(axes.ravel()):
img = Image.open(files[idx])
ax.imshow(img)
Image Data Augmentation
データセット画像の前処理を設定していきます。
train_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
)
val_transforms = transforms.Compose(
[
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
)
- 画像のサイズを224x224Pixelへ統一
- Data Augmentation : 左右反転
- Tensor型へデータ変更
- 正規化
上記を設定していきます。ここではData Augmentationで左右反転のみを実施しますが、↓で他のData Augmentation(RandomErasing、Mixup)についても実施していきます。
データセットのロード
↑の方で示したフォルダ配置に画像を保存している場合、ImageFolderが使えます。実行するだけでデータセット(画像,ラベルのセット)ができる便利な機能です。
train_data = datasets.ImageFolder(train_dataset_dir,train_transforms)
valid_data = datasets.ImageFolder(val_dataset_dir, val_transforms)データをバッチに分けていきます。これで学習データセットのロードは完了です。今回batch_sizeは16でいきますが、GPUメモリが不足している場合は減らすと良いです。
train_loader = DataLoader(dataset = train_data, batch_size=16, shuffle=True )
valid_loader = DataLoader(dataset = valid_data, batch_size=16, shuffle=True)ViTモデルのロード
timmを使ってViTのpre-trained modelをダウンロードし、さらにファインチューニング学習を実行していきます。
model_names = timm.list_models(pretrained=True)
pprint(model_names)['adv_inception_v3', 'bat_resnext26ts', 'beit_base_patch16_224', 'beit_base_patch16_224_in22k', 'beit_base_patch16_384', 'beit_large_patch16_224', 'beit_large_patch16_224_in22k', 'beit_large_patch16_384', ・・・・・・
↑のコードを実行するとロードできるモデル一覧が表示されます。今回は‘vit_base_patch16_224_in21k’を選んでみます。学習する画像のサイズやPCスペックに応じでモデルを変更すると良いと思います。
timmからpretrained modelをダウンロードしてきます。
model = timm.create_model('vit_base_patch16_224_in21k', pretrained=True, num_classes=3)
model.to("cuda:0")pretrain=Trueを指定してください。num_classesは分類するクラス数をしていするので、今回は「A,B,C」の3クラスに指定します。
ViT学習
損失関数、活性化関数の設定をします。今回はクロスエントロピーとアダムでいきます。学習率の設定はここで実施してもOKですが、↑の学習条件の設定で変更してもOKです。
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)学習ループの設定、実行をしていきます。
train_acc_list = []
val_acc_list = []
train_loss_list = []
val_loss_list = []
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
train_acc_list.append(epoch_accuracy)
val_acc_list.append(epoch_val_accuracy)
train_loss_list.append(epoch_loss)
val_loss_list.append(epoch_val_loss)
こんな感じで学習が進んでいきます。
学習結果の可視化
学習曲線を出力していきます。
#出力したテンソルのデバイスをCPUへ切り替える
device2 = torch.device('cpu')
train_acc = []
train_loss = []
val_acc = []
val_loss = []
for i in range(epochs):
train_acc2 = train_acc_list[i].to(device2)
train_acc3 = train_acc2.clone().numpy()
train_acc.append(train_acc3)
train_loss2 = train_loss_list[i].to(device2)
train_loss3 = train_loss2.clone().detach().numpy()
train_loss.append(train_loss3)
val_acc2 = val_acc_list[i].to(device2)
val_acc3 = val_acc2.clone().numpy()
val_acc.append(val_acc3)
val_loss2 = val_loss_list[i].to(device2)
val_loss3 = val_loss2.clone().numpy()
val_loss.append(val_loss3)
#取得したデータをグラフ化する
sns.set()
num_epochs = epochs
fig = plt.subplots(figsize=(12, 4), dpi=80)
ax1 = plt.subplot(1,2,1)
ax1.plot(range(num_epochs), train_acc, c='b', label='train acc')
ax1.plot(range(num_epochs), val_acc, c='r', label='val acc')
ax1.set_xlabel('epoch', fontsize='12')
ax1.set_ylabel('accuracy', fontsize='12')
ax1.set_title('training and val acc', fontsize='14')
ax1.legend(fontsize='12')
ax2 = plt.subplot(1,2,2)
ax2.plot(range(num_epochs), train_loss, c='b', label='train loss')
ax2.plot(range(num_epochs), val_loss, c='r', label='val loss')
ax2.set_xlabel('epoch', fontsize='12')
ax2.set_ylabel('loss', fontsize='12')
ax2.set_title('training and val loss', fontsize='14')
ax2.legend(fontsize='12')
plt.show()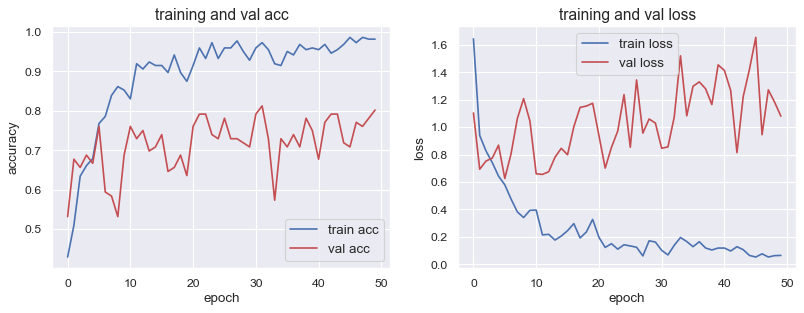
- Validation accuracy : 0.80
- Validation loss : 1.800
と言った結果になりました。ここまでで一通りの学習は完了です👍
結果を確認すると精度はかなり高いと思います。ですがロスのグラフ(右図)を確認すると過学習の傾向がみられると思います。
次に過学習を抑制する目的でData Augmentationを加えていこうと思います。
Data Augmentationを追加する
追加のData Augmentationとして「RandomErasing」と「Mixup」をやってみます。過去の記事でもご紹介したことがあるので、こちらも併せてご覧ください。
RandomErasing
RandomErasingの実装はすごく簡単です。↑のImage Augmentationへ一行追加するだけでOKです。
train_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
transforms.RandomErasing(p=0.2, scale=(0.02, 0.33), ratio=(0.3, 3.3)) # ←ここを追加!!
]
)
val_transforms = transforms.Compose(
[
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
)
test_transforms = transforms.Compose(
[
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
)
RandomErasingはマスクする部分のサイズなどを設定できます。詳しくはここでご確認ください。
↑を実行したあとは同様に学習を実行していくだけです。
結果を可視化すると↓の感じになります。だいぶ過学習は収まったと思います👍
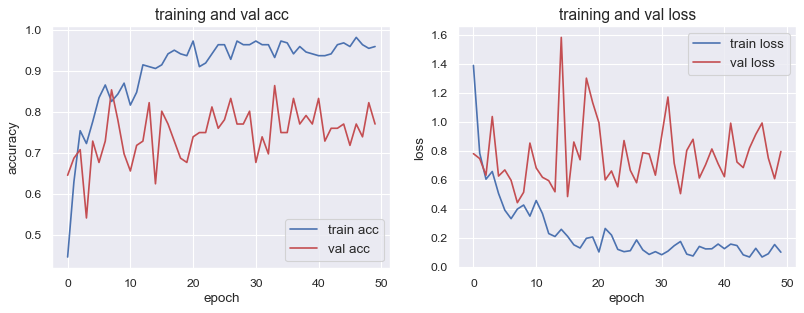
- Validation accuracy : 0.77
- Validation loss : 0.80
Mixup
Mixupの実装は難しくありませんが、RandomErasingほど単純ではありません。
まずはMixupの定義をします。このサイトのやり方を参考にしています。
def mixup_data(x, y, alpha=1.0, use_cuda=True):
'''Compute the mixup data. Return mixed inputs, pairs of targets, and lambda'''
if alpha > 0.:
lam = np.random.beta(alpha, alpha)
else:
lam = 1.
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index,:]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam↑を実行したあとで、学習ループへ↓のように書き換えて実行してください。
train_acc_list = []
val_acc_list = []
train_loss_list = []
val_loss_list = []
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
# ↓ここを追加
data,target_a,target_b,lam = mixup_data(data, label, alpha=1.0, use_cuda=torch.cuda.is_available())
data = data.to(device)
label = target_a.to(device) # target_aへ書換え
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
train_acc_list.append(epoch_accuracy)
val_acc_list.append(epoch_val_accuracy)
train_loss_list.append(epoch_loss)
val_loss_list.append(epoch_val_loss)Mixupついても、どのくらいの割合で画像をブレンドするか設定できます。
学習曲線を出力するとこんな感じになります。
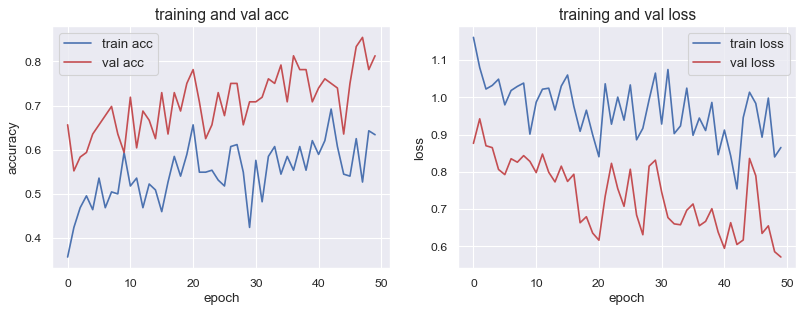
- Validation accuracy : 0.81
- Validation loss : 0.57
だいぶ過学習はおさえられていますが、train accが上がっていないことが気になります。
Data Augmentationのまとめ
Data Augmentationを実行することで過学習はだいぶ抑えられることは分かりました。ですが精度が落ちる傾向がみられるので、どのくらいのあんばいで実施するかテクニックが必要ですね😅
ViTとCNN(EfficientNet)の比較
結局、画像認識タスクでは革命的な技術のViTを使っておけば最適なのか?というところが気になると思います。
そこで今回実装してきたViTのValidation精度と過去に実施したEfficientNetの精度を比較してみます。
データセットは同じモノを使っています。
| EfficientNet | ViT(RandomErasing) | ViT(Mixup) | |
| Validation Accuracy | 0.78 | 0.77 | 0.81 |
| Validation Loss | 0.61 | 0.80 | 0.57 |
ViT(Mixup)がわずかに良い結果となりましたが、EfficientNet(CNN)もかなりいい線いっています。「ViTの方が優れている」と断言はできない結果だと思います。
まとめ
- 独自画像を学習したViTモデルをつくってみました。
- Data Augmentationをいろいろ試すと良い感じで学習できました。
- ViT vs CNNどちらが優れたAIモデルか?については優劣を判断できず、学習データセットの性質・特徴、マシンスペックなどを考慮し適切なアーキテクチャを選択していく必要がありそうです。
- ViTを使ってみて、とりあえずファインチューニング学習を実行すればモデルを高精度に持っていくことができるので、データセットの「質」を見極めることがCNNより簡単そうだと思いました。その辺りが使い勝手がいいのかな?という印象です👍
参考資料
- ImageFolderの利用

- pytorch mixup

コメント