

YOLOv5を使ってスナックエンドウの収穫を楽にしよう!ということで前の記事でやってみました。好評でしたのでスナックエンドウ分類器をパワーアップさせ、実際に使ってみたので感想をまとめます。
前の記事は↓なのでぜひ読んでみてください。YOLOの説明であったり学習の仕方をまとめてあります。

- AI・機械学習を勉強したいけど、何からやればよいか分からない
- 書籍が難しすぎて挫折した
- これからデータサイエンティストを目指したい
- 物体検出が楽しそう
前につくったYOLOv5モデルの分析
スナックエンドウ分類器をパワーアップさせるため、まずは前回つくったモデルについて結果データを見ていこうと思います。まずは学習済モデルを使ったValidationの結果画像を見てみましょう。↓が結果画像ですが、学習後./runs/train/expディレクトリに.jpgファイルが格納されています。

画像を確認していくと、良く見えるスナックエンドウの検出はされているようです。しかし上の画像に注目いただくと、太い茎を誤認識していたり、検出できていないスナックエンドウがあります。↓の画像は一見よさそうですが、よく見ると丸まった葉っぱを誤認識していることが分かります。この時点で物体検出自体は機能しているので学習の進みに問題はない、誤認識が多いのはサンプル数が不足しているもしくは、過学習を起こしているということが懸念されるかな?と思います。
次に結果のデータを見ていきましょう。YOLOv5の学習が終了すると./runs/train/expディレクトリへresults.pngが出てくるので、それを確認していきます。↓が前回つくったモデルの結果です。
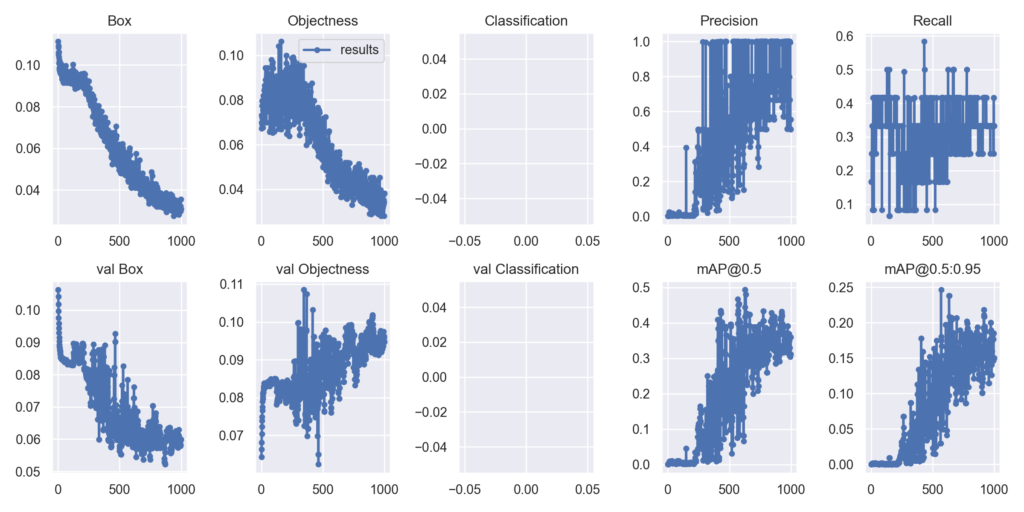
Classification/val Classificationですが今回スナックエンドウしか分類はないので空になっています。yoloの損失関数は難しいのですが、Box, Objectnessで学習が進むにつれてlossが下がるのでいい感じです、一方でval Objectnessを確認すると増加の傾向が伺えます。これは過学習をおこしていると考えられました。
mAP@0.5(クラス1つなのでAPですが)を確認してください。mAPって何?という人はここで詳しく記載されていますのでチェックしてください。mAP@0.5が0.4程度と低い値(0.8程度がいいところ)なので、イマイチといったところです。その原因はRecall値が低いため、取りこぼしが多いことが分かります。これは十分育っていない小さなスナックエンドウもアノテーションしているため?と考えられました。
上記の分析結果より、モデルのパワーアップ方針を下記に決めました。
- サンプル数を増やす
- 過学習のケアとしてepochsを減らす
- アノテーションを見直して収穫可能なモノのみとする
YOLOv5モデルのパワーアップ学習
- サンプル数:34 → 44(旬が終わってたのでたくさん画像とれず…)
- epochs:1000 → 500
- アノテーションやり直し
上記をつくり直し学習を実施します。前につくった学習環境がそのまま使えるので簡単です。AnacondaPromptへ↓コードを入れ実行してください。
conda activate yolov5 #環境アクティベート(前の記事で作成した環境です)
cd Desktop\yolov5
python train.py --data data.yaml --cfg yolov5m.yaml --weights '' --batch-size 8 --epochs 500学習が完了すると./runs/train/expの新しいディレクトリができますので中身を確認しましょう。
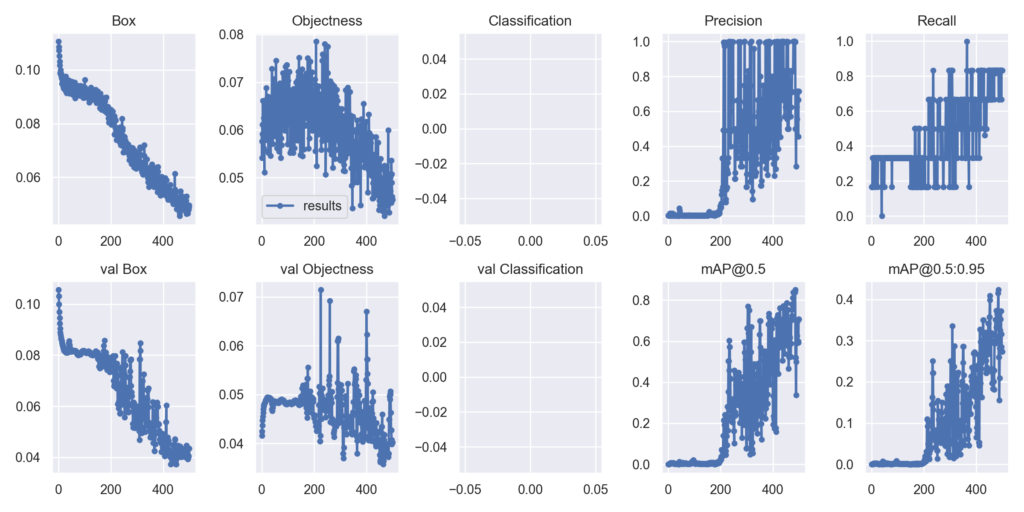
前の記事で問題となっていたObjectnessの過学習がやや改善している(lossが低下している)ことが分かります。mAP@0.5グラフをみると0.8辺りまで改善し良い精度と言えると思います。無事にパワーアップは完了したようです。
パワーアップモデルの性能確認
モデルの性能確認ですが直感的にわかるように動画で実行していきます。動画に対する物体検出方法ですが、簡単です。動画を保存したディレクトリを指定するだけでOKです。
- runs/train/exp**/weightsに入っている重み.ptファイルをyolov5ディレクトリ直下へ移動。私はpower_up.ptへ名前変更しました。**は↑の学習アウトプットディレクトリ。
- 動画データをdata/movies/下へ移動。
- ↓のコードを実行
python detect.py --source ./data/movies/ --weights power_up.pt --conf 0.5ババーっと文字が出てきて落ち着くと、runs/detect/exp**/に物体検出結果がでてくると思います。確認してみましょう。

前回作成モデル

Power up モデル
結果はこんな感じになりました。前回モデルで茎を誤検出することが多かったのですが、Power upモデルは改善しています。だいぶ使えそうな感じがしていますが、見てわかるように枯れ始めておりシーズン終了なので、さらなる検証はお預けとなりました。
まとめと感想
- スナックエンドウの学習データを改良しYOLOv5モデルを高精度化した
- 改良方針はサンプル数増強、過学習ケア、アノテーション見直し
- 改良モデルでmAP:0.8を達成
やってみた感想ですが、思ったより少ないサンプル数でそこそこ精度がでたので良かった。ファインチューニングがすごい。しかし、実際に畑で使おうとするとPCとカメラを持っていく必要があり一人工必要になる。遊んでないで手伝えと言われそう…😂
コメント