

畑で栽培しているトマトが良い感じで収穫できているので、収穫タイミングを判断する物体検出器をつくってみることにしました。トマトと一言にいっても色々な種類があるのですが、今回は「ミディトマト」という種類を見ていきます。ミディトマトとは、大玉トマトとミニトマトをかけ合わせ品種改良したトマトで、酸味が少なく甘いのが特徴的です。
トマトを物体検出する技術はすでに開発されています。またトマトのデータセットなんかもそろっており開発しやすい環境が整ってきていると思います。ですが農林水産省のスマート農業をターゲット?なのか、大がかりなロボットを導入するものが多く敷居が高い感じがします😅
今回は家庭菜園レベルで美味しいトマトを収穫したいじゃん😋というモチベーションでつくっていきます。物体検出アルゴリズムとしてはYOLOv5を使っていきます。また、トマトの物体検出は比較的容易と思います(赤くて目立つ)ので目標は mAP0.5=0.9以上 !高精度モデルをつくるテクニックを紹介していきます。
前の記事でスナックエンドウの物体検出器をつくっています。良かったら併せてご覧ください↓

- 物体検出をやってみたい
- とにかく物体検出を実装してみたい
- これからデータサイエンティストを目指したい
- トマトが好き
YOLOv5の様々な使い方について
当ブログではYOLOv5の様々な使い方を紹介しています。お時間あれば併せてご覧ください。
- 独自データをつかったYOLOv5の学習方法
- 遺伝的アルゴリズムを利用したYOLOv5のパラメータ最適化手法

- YOLOv5で物体検出した画像を切り出して学習データにする方法

データセットを準備
トマトの写真を撮影し、アノテーションしていきます。今回も作業は一人かつ、炎天下のため画像枚数を確保することができず(アノテーションもめんどくさいし・・・)、49枚の画像でトライします。
アノテーションは前の記事でスナックエンドウの画像をアノテーションした手法と同じ方法でアノテーションしていきます。アノテーションデータはYOLO形式(.txt)で保存してください。

- 完熟した収穫時期 : A
- もう少ししたら収穫時期 : B
- 未熟 : C
上記のようにクラス分類しアノテーションしています。これにより、トマトの位置を検出すると同時に収穫タイミングのクラスも出力するモデルをつくっていきます。
YOLOv5学習の前準備
YOLOv5での学習とのことでフレームワークとしてはPyTorchを使っていきます。また、ローカルPCでGPUを使った学習をしていきます。詳細な学習環境についてはこちらをご覧ください。
- PyTorch v1.7.1
- NVIDIA CUDA Toolkit 11.1.1
- NVIDIA cuDNN v8.2.0
ソースコードについては↓を使っていきます。
必要なライブラリはrequirements.txtをインストールしてください。この辺りについてはここに詳細がありますので参照いただけると良いと思います。仮想環境をつくると便利ですので、このあたり不安な方は参照いただけると良いかと思います。
データの準備
データの配置
データのディレクトリ配置は↓図を参照してください。適当にデータをピックアップしてValidディレクトリへ画像とアノテーションデータを配置してください。
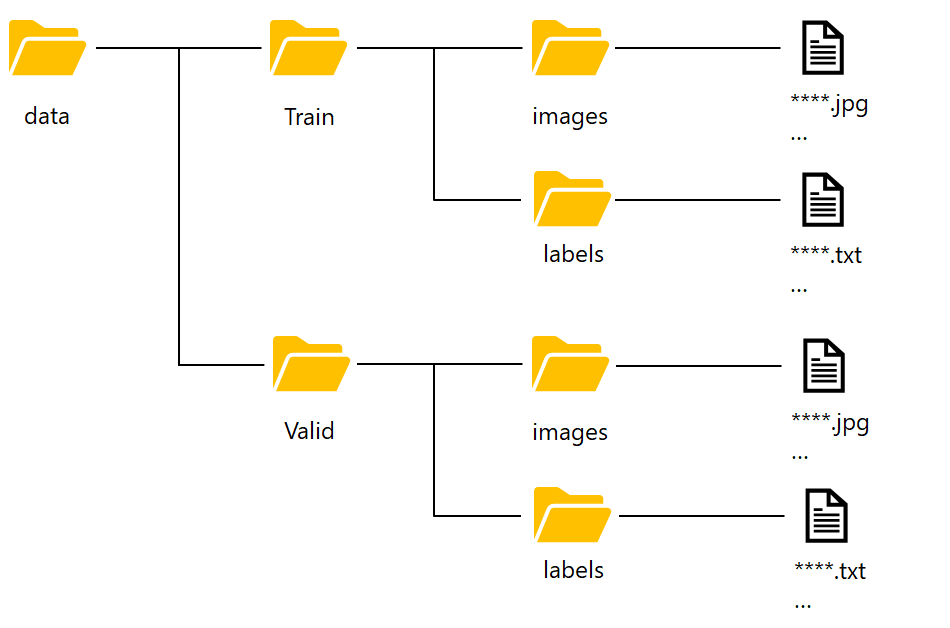
data.yamlファイル作成
dataディレクトリの中にcoco.yamlファイルというモノがあると思います。これをワードパッド等で開いてください。書いてあることを一度全部消します。↓を記入し、”data.yaml”というファイル名でYolov5フォルダ直下へ保存してください。
train: data/train_tomato/images
val: data/valid_tomato/images
nc: 3
names: ['A', 'C', 'B']
YOLOv5学習実行
いよいよ学習していきます。学習実行はAnacondaPromptなどでpythonコードを実行すると簡単に開始できます。まずYOLOv5の作業ディレクトリへ移動して下記コードを実行すると学習がはじまります。
デスクトップへyolov5ディレクトリをつくった場合、↓コードです。
cd desktop/yolov5 #作業ディレクトリの場所を指定してください
python train.py --data data.yaml --cfg yolov5l.yaml --weights '' --batch-size 4 --epochs 1000学習条件①
- cfg : yolov5l.yaml
- epochs : 1000
- batch size : 4
引数–dataはデータの説明で画像の場所だったりラベルと紐付けをします。–cfgは学習モデルs、m、l、xのどれを使うか?を指定します。sは処理が軽いが精度は低い、xは処理が重いが精度は高いという感じになっています。今回はmAP0.9を狙うため、精度重視の「yolov5l.yaml」を使っていきます。epochsは「一つの学習データを何回繰り返し学習させるか」のパラメータで、今回は1000で設定していきます。batch sizeはメモリを考慮し設定してください。一般にはクラス分類数以上なので、今回は4で設定していきます。
結果はこんな感じになりました↓

やはりトマトは目立つので分類しやすく、物体検出はよくできていると思います。ただ、一部認識していなかったり、クラス分類を間違えているところが見られました。学習ログは↓です。
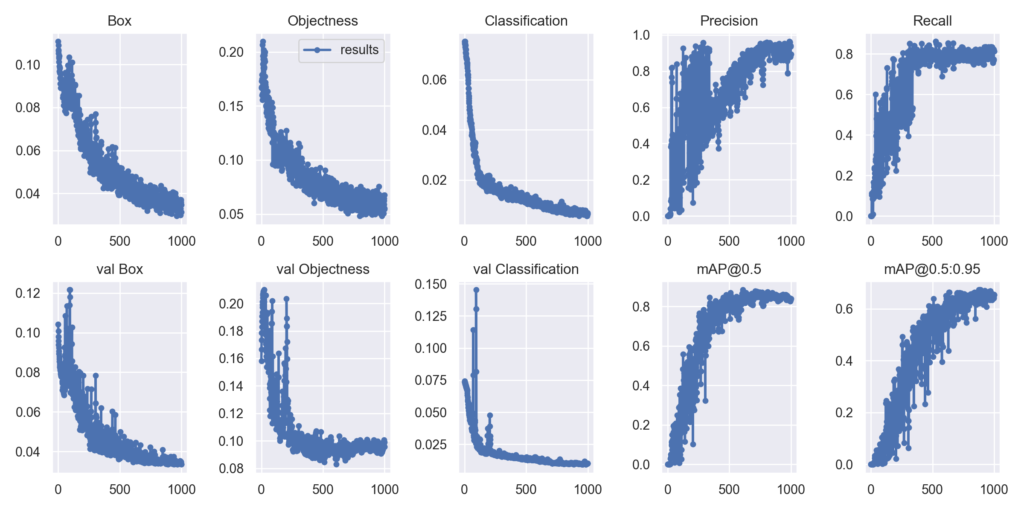
いい感じで学習できていると思います。val lossも下がっていますので過学習もなさそうです。ただ、mAP@0.5をみると、目標の0.9には届かず、「0.8386」というスコアでした。
YOLOv5学習条件①結果の考察
学習結果より↓ 感じに結果を読み取ることができると思います。
- 学習ログをみる限り過学習は見られない
- Box, Objectness, ClassificationのLossが落ち切っていない
Lossが収束していない場合にやれることはepochs数を増やすこと、学習率を変えることなどが考えられますがリスクもあります。
- epochs数を増やす → 過学習のリスク
- 学習率の変更 → 鞍点にハマり学習が進行しなくなるリスク
お手軽に学習トライできる場合は何度も試して確認すれば良いのですが、今回のYOLOv5学習はそこそこ時間がかかるのでやりたくないです。そんな時に有効な手段が転移学習です。転移学習は事前学習の重みを使っていくため、ランダム値(初期設定:–weights ”)からスタートするより収束は早くなります。ということでYOLOv5で転移学習(pretrained重みデータ)を使っていきます。
Pretrainedデータを使う(学習条件②)
pretrainedデータを使うためにコードを書換えます。↓のコードを入力し実行してください。
python train.py --data data.yaml --cfg yolov5l.yaml --weights yolov5l.pt --batch-size 4 --epochs 1000学習条件②
- weights : yolov5l.pt
- epochs : 1000
引数–weightsへyolov5l.ptを指定することで、最新の重みデータが自動でダウンロードされます。これにより学習の収束性向上が期待されます。学習結果は↓です。

学習条件①(YOLOv5)で検出しきれなかった部分を学習条件②(YOLOv5_Pretrained)で検出できているのが分かります。またクラス分類についても精度が上がったように見られます。
学習ログは↓になります。
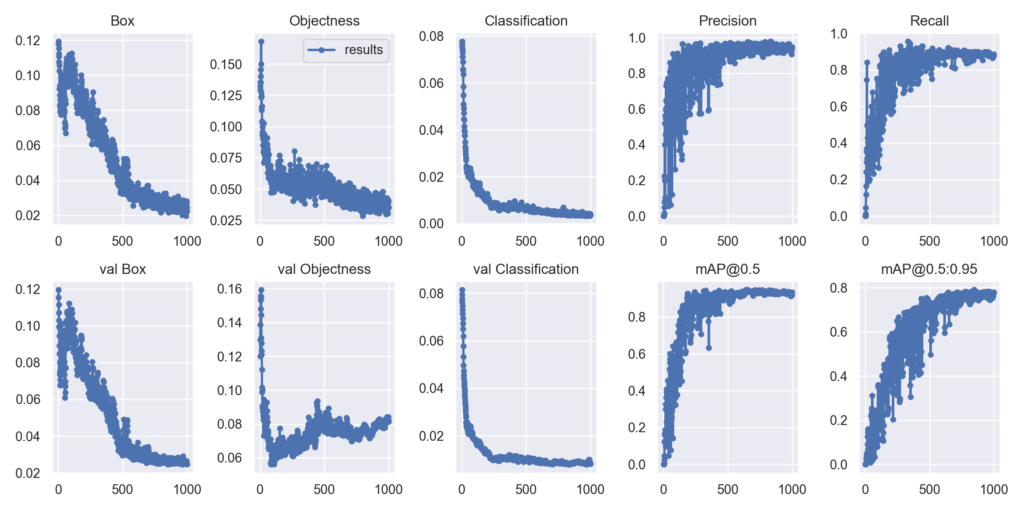
Box, Objectness, ClassificationのLossがほぼほぼ収束しているのが確認できます。またmAP@0.5をみると「0.9327」ということで目標達成しています。
結果を動画で確認してみると↓いい感じで検出できたと思います👍

twitterは↓
まとめ
- ミディトマトの自前画像をつかってYOLOv5物体検出器をつくりました
- Pretrainedデータの有無で学習の収束具合を比較しました
- mAP@0.5=0.93 高精度モデルをつくることができた
前の記事と併せ丁寧に説明してきたので、是非自前データで実装してみてください。
コメント
温井さま。
貴重な情報の公開,ありがとうございます。
マツ枯れの被害樹冠の検出プロジェクトの実施にあたり,常時参考にさせてもらっています。
ふたつ質問があります。
Q1)学習条件(1)のときのmAP@0.5=0.8386,(2)のときの0.9327は,train.py実行後のコンソールにsummaryとして表示されるmAP@0.5の値でしょうか?それとも,result.csvに格納されたepoch別mAP@0.5の最大値でしょうか?
Q2)学習条件(2)のときの,val objectnessのグラフに右肩上がりの傾向がみられますが,この傾向を過学習が起きているとみなすサイトもありますが,過学習は起きていないのでしょうか?
以上,迷える私に助言いただければ幸いです。
小林さん
コメントありがとうございます。
プロジェクトの参考になるほどの物ではないと思いますが、ありがとうございます。
ご質問の件、
Q1:summaryの値で比較しています。
Q2:過学習の傾向はあると思います。ですが過学習の考え方は難しく汎化性能を著しく下げる場合は問題ですが、そうでない場合は過度に気にする必要は無いかと思います。
プロジェクト推進されているとのことですので、まずはアジャイルに実装してみて検証を続けることをおススメします。
その後、精度に問題を感じたら原因を考える方がよいモデルへの近道と思います。
ご参考に!