

前の記事でYOLOv5物体検出で分類しきれなかったモノに、EfficientNetをつかって分類するタスクを紹介しました。EfficientNetモデルが過学習していたので、今回はData Augmentation(データ拡張、データの水増し)を適用して対策していこうと思います。Data Augmentationは注目の技術で多くの手法が提案され続けており、CNNタスクには必須とも言えるモノです。
今回はData Augmentation手法として
- 画像を反転、水平移動、垂直移動(イメージはこちら)
- Mixup、RandomErasing(後述)
といったData Augmentation手法をつかって精度向上を狙ってみようと思います。 全コードは最後にまとめておきますので、お急ぎの方はそちらをご覧ください。
EfficientNetモデルについては↓を併せてご覧ください。

MixUP、RandomErasing Githubは↓をつかっています。
Data Augmenatationをつかう理由
Data Augmentationつかう理由はモデルの汎化性能(未知のデータにも強い性能)を向上させるためです。どういった仕組みでData Augmentationが汎化性能の向上に寄与するか、↓にまとめます。
- そもそもディープラーニング学習には、人間が「当たり前」と思っていることも学習させてあげる必要があります。例えば↓犬の画像を考えてみましょう。人間の場合、全て犬の画像というのが「当たり前」に分かると思います。ですが、もしディープラーニングが「左向き」を犬の特徴ととらえていた場合、向きが変わっただけで答えられなくなります。 Data Augmentationはこれを回避する、つまり当たり前のことを学習させることができます。
- データを取得してみると分かると思いますが、「このデータが少ないかも?!」みたいなことがあると思います。Data Augmentationにはデータの補間的な意味もあるのでこういった場合にも有効です。
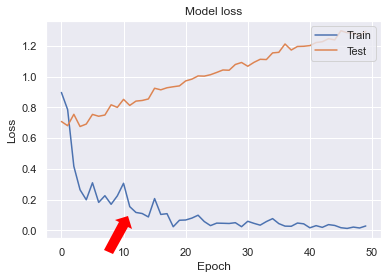
前の記事でEfficientNetモデルが過学習した学習曲線をみると、早期にロスが落ち着き学習の収束がみられます(↓図)。 ここから過剰にTrainデータにフィッティングしていってしまい汎化性能のないモデルとなっています。そこで、Data Augmentationによりノイズを加え学習が収束しずらくしてみる→学習を更新しTestのロスを下げ、モデルに汎化性能を持たせる。っという狙いです👍
Mixup・RandomErasing について
- Mixupとは
2枚の画像をつかってData Augmentationを実施する手法です。イメージは↓図の感じで正常なお米と黒ずんだお米を混ぜるData Augmentationです。これにより分類があやふやな画像を増やすことができます。あやふやな画像の分類を学習することで精度の向上が期待されます。

- RandomErasingとは
画像の一部をマスキングするData Augmentation手法です。イメージは↓図で画像の一部が抜けていることが確認できます。RandomErasingによって期待されることはロバスト性(頑健性)です。分類したいお米が葉っぱや他のお米に隠させてしまってもうまく判定できるようになると考えられます。

これらのData Augmentationを実装していこうと思います👍
EfficientNetで学習
Data Augmentationした学習データをつかってEfficientNetモデルをつくっていこうと思います。全コードは最後にまとめておきますので、お急ぎの方はそちらをご覧ください。
- ライブラリ/学習データセットの準備
前の記事と同じですので詳細はそちらをご覧ください。
- Mixup、RandomErasingのソースコードをダウンロード
↓のGithubのcodeからダウンロードし、解答したファイルを作業ディレクトリ下へ保存してください。
pythonスクリプトのmixup_generator.py、random_eraser.pyが作業ディレクトリ下にあればOKです。
- Data Augmentationのコード
今回は下記2パターンのData Augmentationを試しました。
Data Augmentationパターン①:画像の水平/垂直シフト、水平反転、Mixupを実施
from mixup_generator import MixupGenerator #Pythonスクリプトの読込み
batch_size =32
#keras_Data_Augmentation:水平/垂直移動、水平反転
datagen = tf.keras.preprocessing.image.ImageDataGenerator(width_shift_range=0.1, #ランダムに水平シフトする範囲
height_shift_range=0.1, #ランダムに垂直シフトする範囲
horizontal_flip=True) #水平方向に入力をランダムに反転
#Mixup
training_generator = MixupGenerator(x_train, y_train, batch_size=batch_size, alpha=0.4, datagen=datagen)()
#x_trainは画像データ、y_trainはラベルデータです。alphaは2枚の画像のブレンド割合
Data Augmentationパターン②:上記に追加しRandomErasingを実施
from random_eraser import get_random_eraser
batch_size =32
#keras_Data_Augmentation + RandomErasing
datagen2 = tf.keras.preprocessing.image.ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
preprocessing_function=get_random_eraser(v_l=0, v_h=255)) #RandomErasing
training_generator2 = MixupGenerator(x_train, y_train, alpha=0.4, datagen=datagen2)()
- EfficientNet学習
- ベースモデル:EfficientNet-B0
- epochs = 50
- batch_size = 32
- オプティマイザー:Adam(lr=0.01)
学習結果の確認
- 学習結果の可視化
各エポックvsロスの学習曲線グラフを示します。
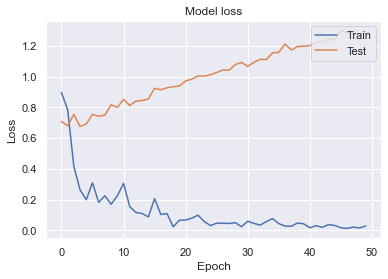

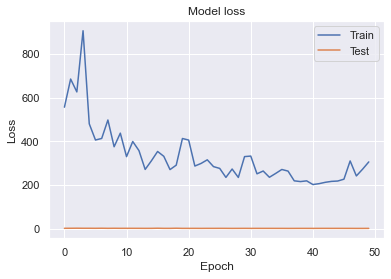
Data Augmentationパターン①(Mixup)で過学習が収まりバランスよく学習できたと思います。Data Augmentationパターン②(Mixup⁺RandomErasing)はTrainデータのロスが収まらず上手く学習できませんでした。黒い斑点が隠されると分類が難しいためRandomErasingは向いていないと考えられました。
- 精度、誤差の比較
Validation AccuracyとValidation Loss(検証用データを用いたモデルの精度と誤差)は↓の表となります。
| Data Augmentation なし | Data Augmentation パターン① | Data Augmentation パターン② | |
|---|---|---|---|
| Validation Accuracy | 0.695 | 0.777 | 0.535 |
| Validation Loss | 1.275 | 0.605 | 1.445 |
Data Augmentationパターン①で最も良い結果となりました。学習に使用していないValidationデータを用いても精度78%で正解を出すということで、そこそこいい感じにまとまったと思います。
- 推論結果


Data AugmentationなしとData Augmentationパターン①を比較すると、パターン①は明らかに間違えているラベルは無くなっているように見えます。全データ見たわけではありませんが、人でも判断に迷いそうなモノを間違えているのかな?という印象です。(私のラベル付けが良くない可能性もあり)
- まとめ
EfficientNetモデルが過学習していた問題についてはData Augmentation(Mixup)を適用し改善しました。Data Augmentationは簡単に実装できる上に効果絶大ですので、積極的に組み込んでみてください👍
全コード
import tensorflow as tf
from tensorflow.keras.utils import to_categorical
import numpy as np
from sklearn.model_selection import train_test_split
from PIL import Image
import glob
import matplotlib.pyplot as plt
import tensorflow_hub as hub
from tensorflow.keras import layers
from mixup_generator import MixupGenerator
from random_eraser import get_random_eraser
import seaborn as snsfolder = ['A', 'B', 'C'] #分類するクラス
image_size = 64 #インプット画像のサイズ
X = []
Y = []
for index, name in enumerate(folder): #ディレクトリの種類、画像ファイル名を繰返し取得する
dir = "./rice/" + name #ご自身のディレクトリ名を指定してください
files = glob.glob(dir + "/*.jpg") #ファイル名の取得
for i, file in enumerate(files): #各画像へ↓の処理を繰返し実施する
image = Image.open(file) #画像の読み込み
image = image.convert("RGB") #RGBに変換
image = image.resize((image_size, image_size)) #サイズ変更
data = np.asarray(image) #画像データを配列へ変更
X.append(data) #画像データを繰返し追加
Y.append(index) #daisy:0, dandelion:1の値を繰返し追加
X = np.array(X)
Y = np.array(Y)
#画像データを0~1の値へ変換
X = X.astype('float32')
X = X / 255.0
#正解ラベルの形式を変換
Y = to_categorical(Y, 3)
#学習用データとテストデータへ分割
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.30)#Data Augmentation
batch_size =32
datagen = tf.keras.preprocessing.image.ImageDataGenerator(width_shift_range=0.1, #ランダムに水平シフトする範囲
height_shift_range=0.1, #ランダムに垂直シフトする範囲
horizontal_flip=True) #水平方向に入力をランダムに反転
#, preprocessing_function=get_random_eraser(v_l=0, v_h=255) #RandomErasingを使う場合はコメントアウトを外してください
)
#Mixup
training_generator = MixupGenerator(x_train, y_train, batch_size=batch_size, alpha=0.4, datagen=datagen)()
#x_trainは画像データ、y_trainはラベルデータです。alphaは2枚の画像のブレンド割合#EfficientNet
#B0
feature_extractor_url = "https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1"
feature_extractor_layer = hub.KerasLayer(feature_extractor_url,
input_shape=(64,64,3))
feature_extractor_layer.trainable = False
model = tf.keras.Sequential([
feature_extractor_layer,
layers.Dense(3, activation='softmax')
])
model.compile(
optimizer=tf.keras.optimizers.Adam(lr=0.01),
loss='categorical_crossentropy',
metrics=['acc'])
epochs = 50
train_steps_per_epoch = np.ceil(int(x_train.shape[0]/batch_size))
val_steps_per_epoch = np.ceil(int(x_test.shape[0]/batch_size))
history = model.fit_generator(generator=training_generator,
epochs=epochs,
steps_per_epoch=train_steps_per_epoch,
validation_data = (x_test, y_test),
validation_steps=val_steps_per_epoch)#学習曲線の可視化
sns.set()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper right')
plt.show()#検証用データでの精度と誤差
test_loss, test_acc = model.evaluate(x_test,y_test)
print('test loss:', test_loss)
print('test acc:', test_acc)class_names = np.array(['A','B','C'])
predicted_batch = model.predict(x_test)
predicted_id = np.argmax(predicted_batch, axis=-1)
predicted_label_batch = class_names[predicted_id]
label_id = np.argmax(y_test, axis=-1)
plt.figure(figsize=(10,9))
plt.subplots_adjust(hspace=0.5)
for n in range(30):
plt.subplot(6,5,n+1)
plt.imshow(x_test[n])
color = "green" if predicted_id[n] == label_id[n] else "red"
plt.title(predicted_label_batch[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (green: correct, red: incorrect)")関連書籍・撮影機材
ディープラーニングやお米の栽培で参考書籍を紹介します。バケツでも栽培できるようなので気になる方は是非やってみてください👍
画像/動画撮影はiphone11ですが、できるだけブレないように三脚・グリップで固定して使っています。関連機材を紹介します。
コメント
はじめまして。
現在画像認識モデルや物体検出モデルなど様々なディープラーニング(モデル)を勉強中の学生です。Nukuiさんのブログは大変タメになるものが多く、いつも読ませていただいております!
質問といいますか単なる興味といいますか。。。
本記事と前回の記事では学習済みのEfficientnetを使用しお米を転移学習させていますが、転移学習せず切り出したお米を一から学習させた場合、学習済モデルとどのくらいの精度の差があるのかが気になりました。お時間がありましたら検証してみてほしいです!
これからもNukuiさんのブログ楽しみにしてます~