

セグメンテーションをやりたい!と思って一番苦労するのはデータセットの準備でしょう😂ここではアノテーション、画像サイズなど、データセットの作成をやっていきます。
セグメンテーションは入力画像データに対し、ピクセル単位で「背景」「対象」を分類するアルゴリズムになります。そのため、入力データと同じ解像度の出力データが必要になり、それらをデータセットとする必要があります。以前実施したCNN(画像認識)やYOLO(物体検出)に比べデータセットをつくるのは大変になるのが理解できると思います。
- 書籍が難しすぎて挫折した
- これからデータサイエンティストを目指したい
- 画像データのディープラーニングに興味がある
- 独自の画像データでディープラーニングをしたい
ニューラルネットワークの基本を理解されている方を対象としています。基本を知りたい方は過去の記事も併せてご覧ください↓

セグメンテーションとは何ぞや❓という方は↓で説明していますので併せてご覧ください。

スナックエンドウ画像のデータセット加工(アノテーション)
さて、セマンティックセグメンテーション用のデータセットを作成していこうと思います。適当なアノテーションソフトがあるのか?よくわからなかったので、ここではGIMPというフリーソフトを使っていこうと思います。具体的な手順を説明していきます。
GIMPをインストールしたら起動し、ファイル→開く/インポートより処理したい画像を開いてください。
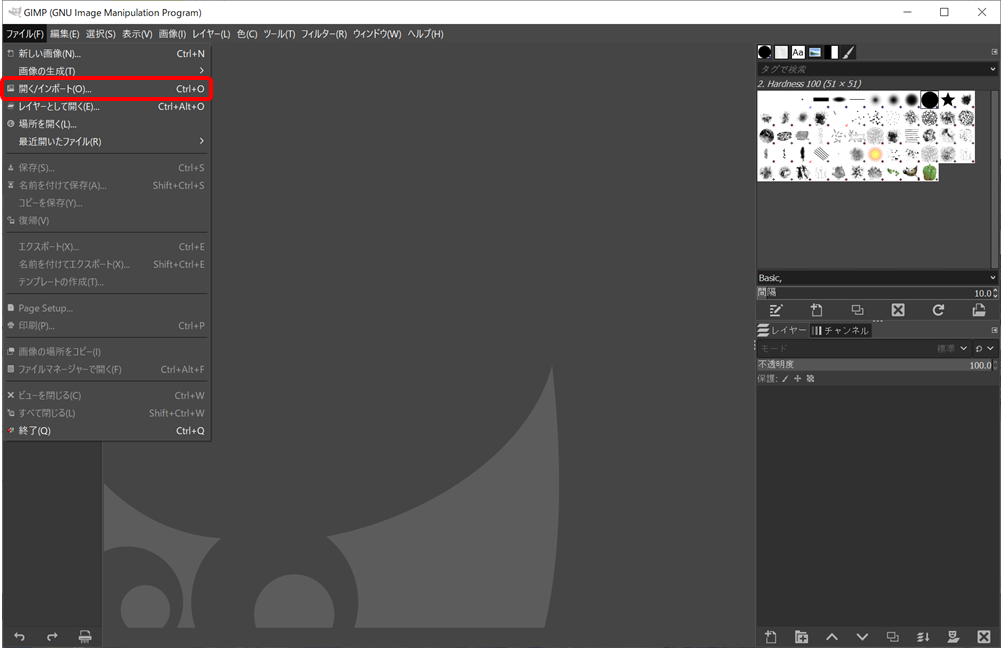
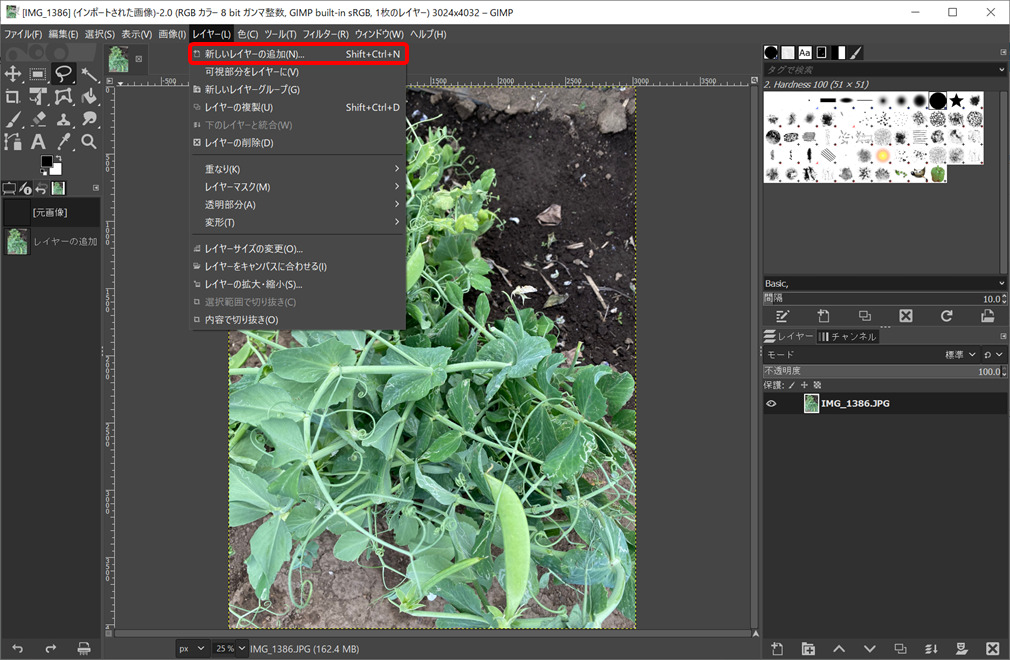
画像を読み込んだらアノテーション画像を別レイヤーへ描くため、新しいレイヤーを追加していきます。レイヤー→新しいレイヤーの追加を選択して、新しいレイヤーを作成してください。
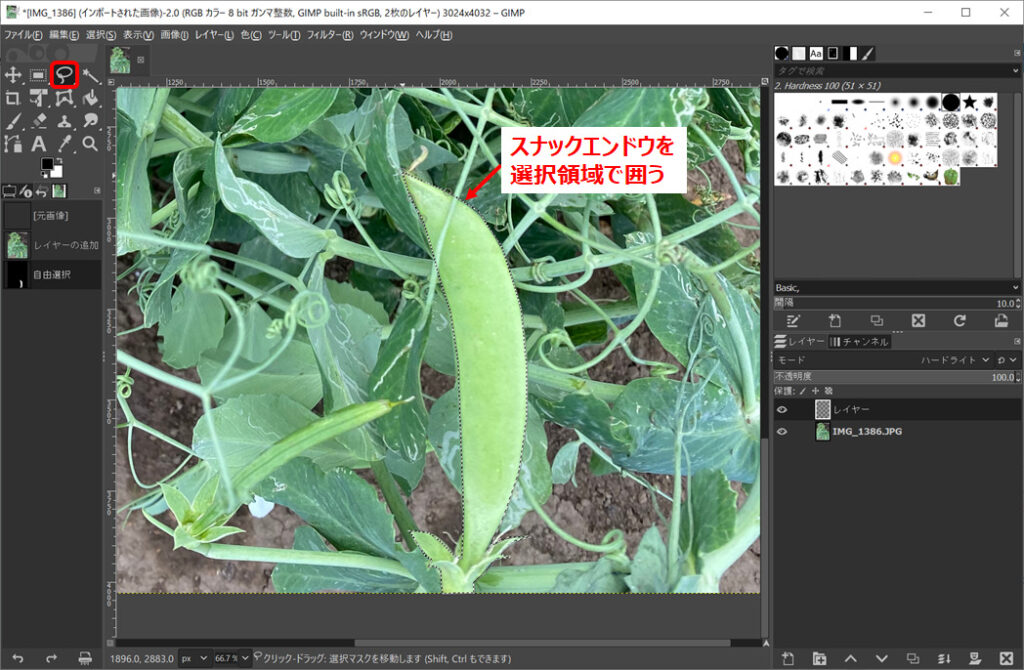
自由選択ツールでスナックエンドウの周囲を選択領域として囲ってください。
選択範囲を白く塗りつぶします。
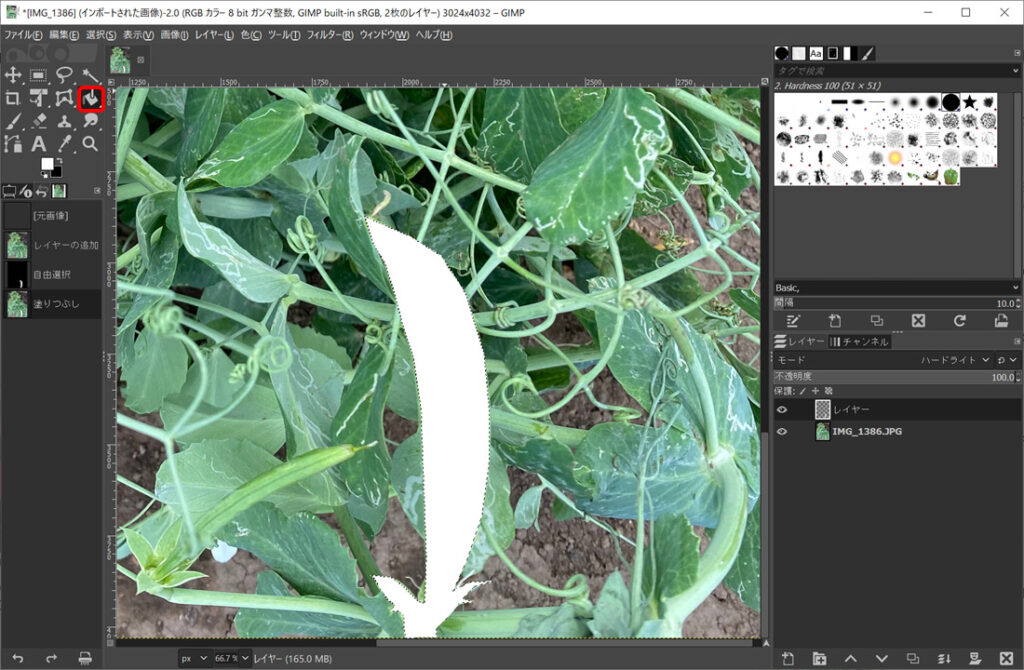
以上の手順を画像中のすべてのスナックエンドウに実施します。今回は2値分類ですが、他クラス分類したい場合は白と赤など、違った色でアノテーションすると良いと思います。
すべてのスナックエンドウを白く塗りつぶした後、背景を黒く塗っていきます。黒色を選択後、塗りつぶしツールで背景を黒く塗ってください。
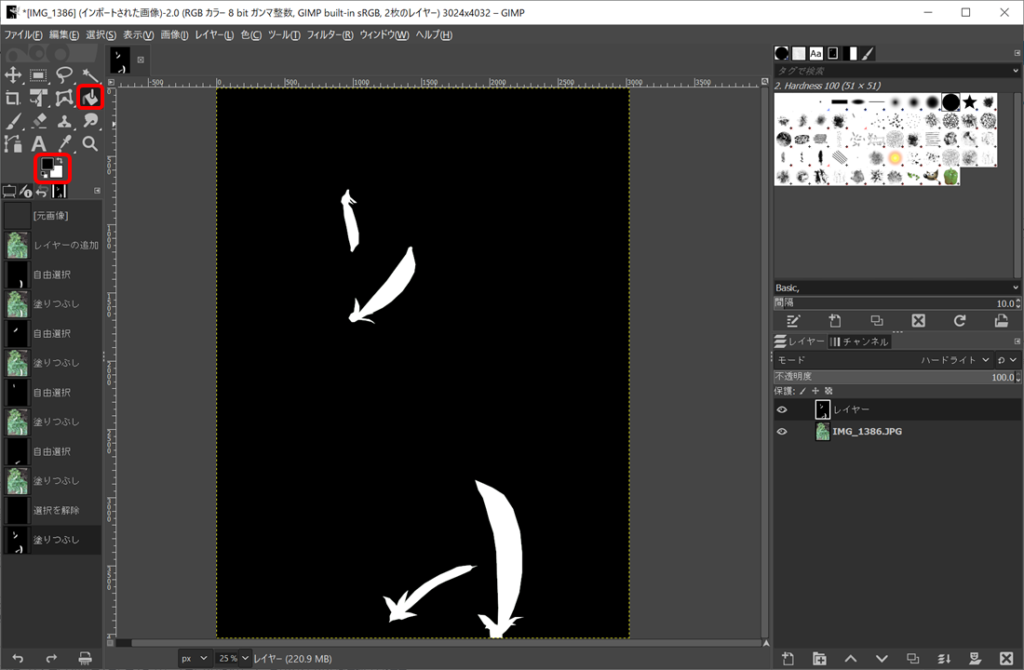
最後に保存してアノテーションは完了です。保存はファイル→名前を付けてエクスポートで保存してください。ファイル名は入力画像と同じ名前とし、別のフォルダへ保存すると良いです。
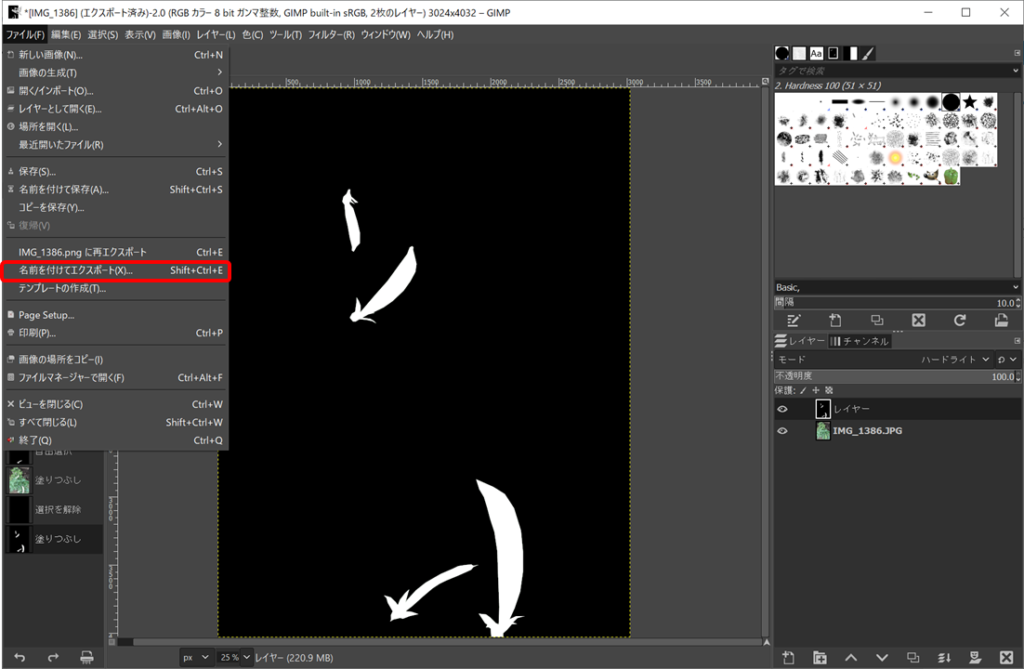
上記の作業を全ての画像について実施します。かなり大変な作業ですが気合で頑張りましょう。。。
画像解像度について
最近のデジカメ、iphoneなどで撮影した画像📷はキレイですよね。その分解像度は大きく、一つ当たりの画像容量も大きくなっています。このままの状態でディープラーニングすることも可能ですが、おそらく直ぐにOOM(Out Of Memory)が発生してしまいます。ディープラーニングはできるだけ多くの画像を使うと精度向上が期待できますが、一方でOOMの問題を同時に考えていく必要があります。
そこで、ディープラーニングの際は画像解像度を小さくするのが普通です。画像解像度を小さくしても、そこに存在するモノが認識できれば問題ないのでガッツリ小さくしていきましょう。
解像度の変更はGIMPで実施してもいいのですが、データセットすべてで実施していくのが面倒です。Pythonで実施すると簡単なので、コードを置いときます↓
import cv2
import glob
def scale_to_width(img, width):
h, w = img.shape[:2]
height = round(h * (width / w))
dst = cv2.resize(img, dsize=(width, height))
return dst
name_list = glob.glob("./data/*.jpg") #画像が保存されているフォルダを指定してください
for name in name_list:
img = cv2.imread(name)
dst = scale_to_width(img, 320) #解像度を記入してください。最大一辺320pixel
cv2.imwrite(name, dst)まとめ
- セグメンテーション用のデータセット作成をフリーソフトGIMPを使ってやってみた
- 画像認識や物体検出と比べるとセグメンテーションのデータセット準備は時間がかかる
- ディープラーニングはできるだけ多くのデータを使いたいので画像解像度を小さくし、OOMを防ぐ必要がある
次回は、セマンティックセグメンテーションの学習を実施していこうと思います。
コメント