

スナックエンドウの画像を使ったセマンティックセグメンテーションを過去の記事で紹介しました。あまり上手くいかなかったので、今回はリベンジを兼ねてトマトの動画を使ったインスタンスセグメンテーション(Instance Segmentation)に挑戦してみようと思います。YOLACT(You Only Look At CoefficienTs)という物体検出アルゴリズムのYOLOから派生したモデルに独自のトマト画像を学習させインスタンスセグメンテーションモデルをつくっていきます👍
セマンティックセグメンテーションモデルをいくつか公開しております。↓に詳細を記載しています。併せてご覧ください。



インスタンスセグメンテーション
インスタンスセグメンテーションについて
インスタンスセグメンテーションはセグメンテーションタスクの一種です。↓の図の右端がインスタンスセグメンテーションによる分類結果で、一人一人が分類できる特徴があります。一方で、前の記事で紹介したセマンティックセグメンテーションは↓の図の真ん中で「人」は一つのまとまりとして分類します。セグメンテーションタスクについて詳細をここを参照してください。

YOLACTについて
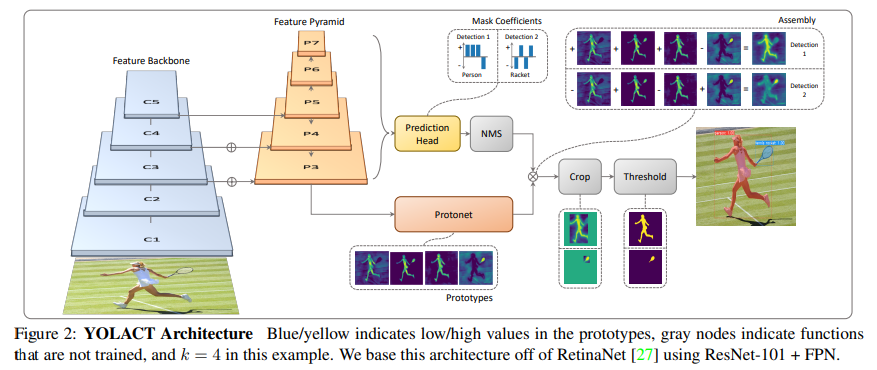
YOLACTはインスタンスセグメンテーションアルゴリズムの一種です。YOLOのような物体検出と、セマンティックセグメンテーションのような分類タスクを合わせ持ったモノになります。↓図のようにラベルは「motorcycle」ですが、2台をそれぞれセグメンテーションしています。

どうやるか?というとセマンティックセグメンテーション(Protonet)と物体検出のアルゴリズム(Prediction Head)を同時に実施した後に、それらをAssembly(組み合わせる)ことで達成しています。詳細は論文を参照してください。
学習準備
使用PCスペック
- Windows 10
- CPU : AMD Ryzen 7 5800
- GPU : RTX3070 8GB
事前準備としてCUDA、cudnnのインストールします。この辺りはここに詳しく掲載されているので、その通りにインストールしています。インストールしたバージョンは下記です。
- NVIDIA CUDA Toolkit 11.4
- NVIDIA cuDNN v8.2.0
ソースコード
Yolactを↓のサイトからダウンロードしてください。ダウンロードの方法が不明な場合はここを参照すると良いかと思います。
ライブラリ
必要なライブラリをインストールしていきます。PyTorchはご自身のCUDAのバージョンに合わせインストールしてください。ここでpipコードを調べることができます。
conda create --name=yolact python=3.6
conda activate yolact
pip install cython
pip install opencv-python pillow pycocotools matplotlib
pip3 install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio===0.9.1 -f https://download.pytorch.org/whl/torch_stable.html独自画像のアノテーション
何はともあれ、独自画像をつかうためにはアノテーションが必要です。アノテーションって何ぞや?という方はここをご覧いただくと良いかと思います。
今回はlabelmeというアノテーションライブラリをつかっていきます。詳細は↓のGithubを参照ください。
labelmeのインストール
pip installでインストールできます。AnacondaPromptなどで↓のコードを実行してください。
conda create --name=labelme python=3.6
conda activate labelme
pip install labelme
labelmeコードを実行するとlabelmeが起動すると思います。
labelmeの使い方

- OpenDir をクリックし画像が保存してあるディレクトリを指定します。
- File → Change Output Dir をクリックしアノテーションデータを保存するディレクトリを選択します。
- Create Polygonsをクリックしアノテーション対象を囲んでいきます。囲めるとEdit windowが出てきますのでお好みのラベルを入力してください。
- 画像中のすべてのアノテーションが完了しましたらSaveをクリックしアノテーションデータを保存してください。ファイル種類は.jsonで保存してください。
- 上記の手順を全ての画像データで実施してください。
今回は次のようなラベルを付けることとしました。
- 完熟した収穫時期 : A
- もう少ししたら収穫時期 : B
- 未熟 : C
***.jsonファイルの変換
labelmeの使い方は以上ですが、Yolactの学習データ準備としてはもう少しデータ変換をする必要があります。↓のソースコードをgit clone かダウンロードしてください。
ダウンロードできましたら先ほどアノテーションした.jsonファイルが格納されているディレクトリをコピーします。↓のディレクトリ構造としてください。
labelme
-> examples
-> instance_segmentation
-> train_label #名前は任意です
1.json
2.json
3.json
4.jsonディレクトリ移動したついでにlabel.txtを編集します。instance_segmentationディレクトリ下にlabet.txtというファイルがあると思います。これをアノテーションした内容へ変換します。今回の場合は↓になります。label.txtを↓へ書き換えて保存すればOKです。
__ignore__
_background_
A
B
CAnacondaPromptなどで↓のコードを実行してください。
conda activate labelme
cd Desktop/labelme/examples/instance_segmentation #作業ディレクトリlabelme
./labelme2coco.py train_label train_coco --labels labels.txt #json格納ディレクトリ名は↑で指定したモノへ変更してください
実行すると変換が始まり、train_cocoというディレクトリが生成されると思います。中に「JPEGImage」「Visualization」「annotations.json」が入っていればOKです。最初にダウンロードしたyolact/dataディレクトリへ↓のようにtrain_cocoディレクトリを移動してください。
yolact
-> data
-> train_cocoちなみにvalidationデータについても同様にアノテーション→.json変換→ディレクトリ移動で準備してください。推論(学習に使っていないデータ)で使用できます。
YOLACTを動かす
config.pyの修正
動かす前にもう一つ作業があります。yolact/dataディレクトリ下にあるconfig.pyへ独自データセットを登録する作業を実施していきます。2つの作業があります。
作業1:config.pyを開いてもらい(ワードパッドなどでも可)– DATASETS –を探してください。–DATASETS–の一番下へ以下のコードを追記してください。
my_custom_dataset = dataset_base.copy({
'name': 'My Dataset',
'train_images': './data/train_coco',
'train_info': './data/train_coco/annotations.json',
'valid_images': './data/val_coco',
'valid_info': './data/val_coco/annotations.json',
'has_gt': True,
'class_names': ('A', 'B', 'C')
})作業2:– YOLACT v1.0 CONFIGS –を探してください。以下に示すようにcoco2017をmy_customへ書き換えてください。
'dataset': coco2017_dataset,
'num_classes': len(coco2017_dataset.class_names) + 1,
↓
'dataset': my_custom_dataset,
'num_classes': len(my_custom_dataset.class_names) + 1,事前学習済みデータのダウンロード
今回はCOCOで事前学習済みデータをつかって転移学習していきます。YOLACTのGithubの中段Evaluationの表にある「yolact_base_54_800000.pth」をダウンロードしてください。ダウンロードした事前学習済みデータは、yolact/weightsディレクトリ下へ格納してください。
いよいよ学習
以下のコードを実行してください。学習が実行されると思います。
conda activate yolact
cd Desktop/yolact #ご自身の環境で作業ディレクトリへ移動してください。
python train.py --config yolact_base_config --resume weights/yolact_base_54_800000.pth --start_iter 0 --batch_size 4 --num_workers 0 --validation_epoch -1引数を簡単に説明すると
- –config : 学習のコンフィグ。↑で設定した独自データのコンフィグに合わせてあります。
- –resume : 事前学習済みデータを指定し、そこからレジュームしていきます。
- –start_iter : レジューム学習をどのイテレーションからスタートするか。今回は0です。
- –batch_size : バッチサイズ。GPUメモリと相談して数値を決めましょう。私の環境では4です。
- –num_workers : ミニバッチの取り出し処理。今回は0(single process)です。
- –validation_epoch : ここが今回の一番の問題。validationをやろうとするとOOMになって学習が止まってしまいます。そこで今回は-1(validation無し)に設定。
学習後のLOSS
LOSS{”B”: 0.54477, “M”: 1.30263, “C”: 0.86308, “S”: 0.04375, “T”: 2.75423}, “epoch”: 106, “iter”: 1068, “lr”: 0.0005
ロスが安定してきたので、↑で学習ストップしました。ちなみにCTRL+Cで学習を中断でき、重みデータはweightsディレクトリ下へ保存されます。保存された学習データは推論で使うので名前を変更しておきます。
yolact_base_106_1069_interrupt.pth
↓
yolact_base.pth結果を見てみる
↓のコードを実行するとインスタンスセグメンテーションの推論を実行することができます。
python eval.py --trained_model weights/yolact_base.pth --images ./data/val_coco/JPEGImages/:./output_images
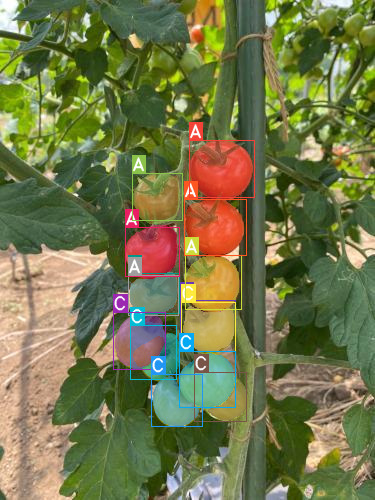




いい感じでインスタンスセグメンテーションできました。一つ一つのトマトを認識しているし、ラベルも合っています。
動画についても↓のコードで一発推論することができます。
python eval.py --trained_model weights/yolact_base.pth --video ./data/movie/input_video.MOV:output_video.mp4独自データでYOLACTを学習することができました。アノテーションがかなり大変ですが、相応の威力はあると感じています。是非お試しあれ👍
コメント
大変参考になる記事ありがとうございます。
今、セグメンテーションされた領域のピクセル座標(整数)を取得したいのですがどうのようにしたらいいのか分かりません。
もしよろしけれど教えていただきたいです。
よろしくお願いします。
松沢さん
コメントありがとうございます。
↓のissueでマスク画像を取得するコードが公開されています。
https://github.com/dbolya/yolact/issues/642
これを上手く使えば座標値を取得できると思います。
お試しください。
DL自体をこれまで使ったことがありませんでしたが、記事を参考にyolactが使えるようになりました。
有益な記事ありがとうございます。
ともさん
コメントありがとうございます。
お役に立ててよかったです!