

農作物でAIをつくろうとするとデータの取得に苦労します。なぜなら農作物は収穫のタイミングが決まっており年に1~2回程度です。しかも収穫は基本忙しいので悠長にデータを取得している余裕はありません😅。逆に冬場は作物があまり育たないのでデータは少ないです。
そうなると、何とかして安定的にデータを取得したいですよね。Webでスクレイピングする方法があるんですが良い画像を集めるのは難しい上、そもそもスクレイピングが違法の国もあります。
そこで今回はDALL・Eを使って画像を生成し、それを使ってみるという挑戦です。ですが、”Garbage In, Garbage Out”というG検定受験者にはお馴染みの言葉もあるように、適当に生成した画像を入れても精度は向上しない!と思いますよね😥。私も最初はそう思いました。試しにDALL・E miniで生成してみると↓

思ったよりリアルな画像がでてきました!?正直DALL・Eを過小評価していたところがあります。生成した画像に対し過去につくった物体検出モデル(YOLOv5)で推論してみた結果が↓です。

意外といけそうなんじゃないか!?という気持ちになり、DALL・E miniでいくつか画像を生成して、過去につくった物体検出モデルを強化してみました👍
DALL・E miniを使う
DALL・E miniを使う前にDALL・Eの歴史をざっくりと。
DALL・Eは入力したテキスト文章から、その意味を読み取って画像を生成するAIです。DALL・Eは2021年1月にOpenAIに発表されました。当時、他に類を見ないAIモデルだったので世界に衝撃を与えました。そしてOpenAIは2022年4月により高画質な画像を出力できるDALL・E2を発表しています。
DALL・Eを使ってみたい!となるんですが、招待制となっており応募~当選しないと使えない敷居の高いモノでした。
そこで登場したのがDALL・E miniです。これはブラウザ上で文章テキストを入力し実行するだけで、数分待つと画像が出てきます!↓のサイトで文章(英文)を入れて”RUN”を押してみてください。

試しに”Darth Vader harvesting snap peas”スナップエンドウを収穫するダースベーダーと入れてみます。

こんな感じでライトセーバーでスナップエンドウを収穫するダースベーダーが出力されました👀
DALL・E miniだけでも楽しいので遊んでみても良いと思います👍
DALL・E mini生成画像をYOLOv5で物体検出してみる
DALL・E miniでリアルな野菜の画像が生成できました。これを物体検出したらどうなるか!?やってみた結果が↓になります。過去につくったモデルを使っています。

物体検出が反応する場合と全く反応しない場合に分かれました。どういう場合に反応しないのか?よくわかりませんが、陰影がはっきりしている場合(絵画っぽい?)に反応していないように見えました。
トマトでもやってみます。これも過去につくった物体検出モデルを使います。

トマトも同じで反応する場合と全く反応しない場合に分かれました。物体検出がどういう基準で判断しているかは全く分からないですが、どうやら物体検出モデルから言わせると「別モノ」が生成されているようです。。。😅
これをそのまま学習データとして採用しても精度が上がらないどころか、下げる結果となる危険もあると思います😂
ここまでで考察すると、DALL・E生成画像は学習データとして使わない方が良いという結論になります。
DALL・E mini生成画像をYOLOv5の学習データに加えてみる
やるな!と言われると、やりたくなってしまう。。。素晴らしい性格なのでDALL・E miniで生成した画像を使って物体検出器をつくってみます。
とは言え闇雲にデータを増やすのではなく、過去の物体検出モデルを通して反応した画像だけを使ってみます。
下記条件で学習していきます。物体検出モデルの実装が分からない!という方は過去の記事を参考にしてみてください。また、最後に過去の記事をまとめておくので、そちらも参照してみてください。
学習データセット ・スナップエンドウの画像75データ ・20データをDALL・E mini生成画像 物体検出モデル ・YOLOv5 ・過去学習重みを用いファインチューニング ・100 epochs
結果は以下の通りです。
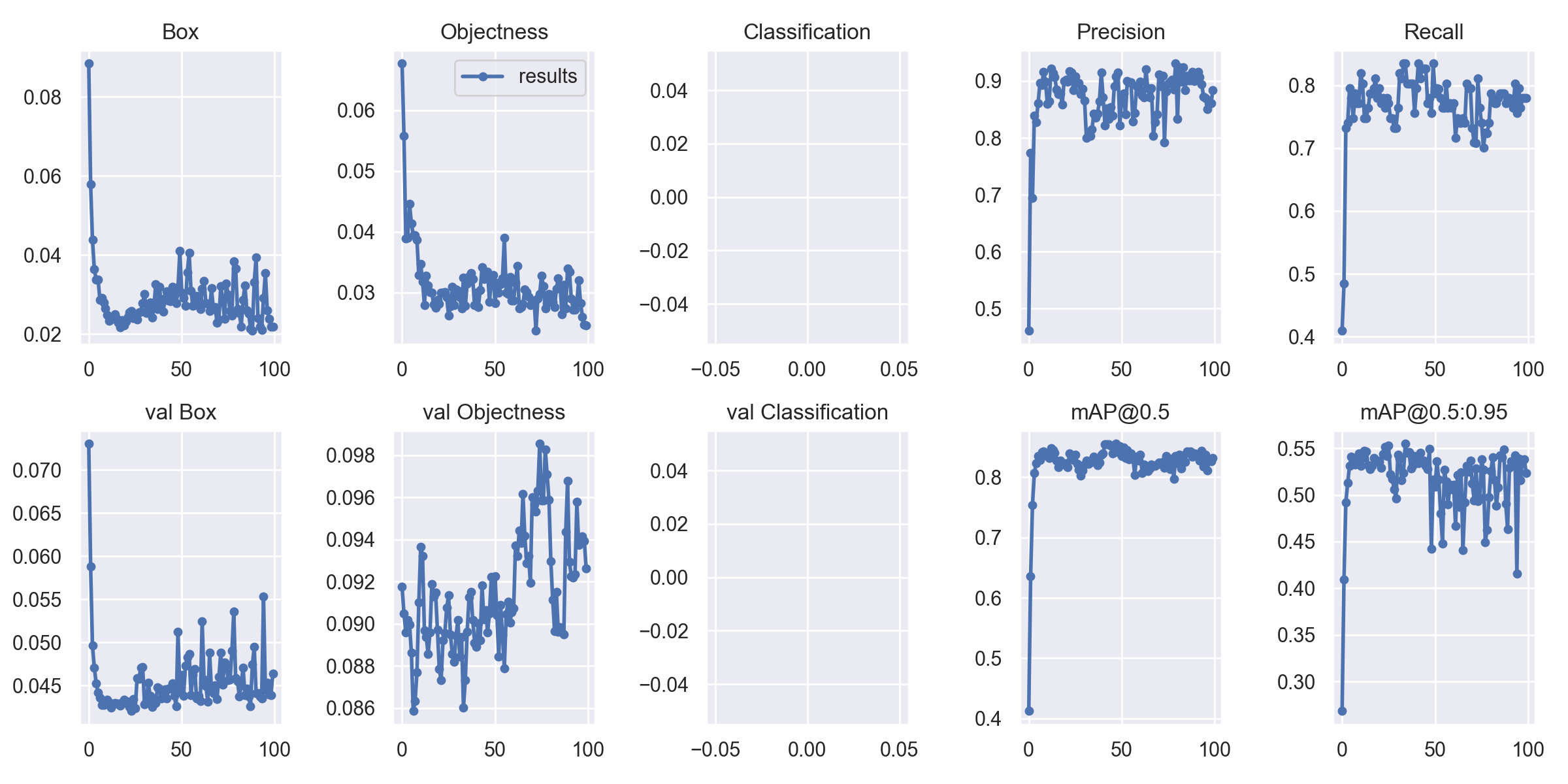
以外とイイ感じで学習が進行していると思います。あれ?悪くないじゃんといった感じです。過去に学習したモデルのmAP@0.5が0.85程度ですので、精度が上がったとは言えませんが下がっては無いと思います。
物体検出は数値だけではモデルの良し悪しが分からないので検証データでの出力を「オリジナルデータを使ったモデル」と「DALL・E mini生成画像を追加したモデル」で比較してみます。

オリジナルデータのモデルでは検出できなかったスナップエンドウを検出できるようになってますが、余計なところも検出してしまっている。過学習の傾向がある?

別の写真で検証すると、これはいい感じです。オリジナルデータのモデルだと隣のプランターのネギを検出してしまっていますが、誤検出が改善しています。

また別の画像で検証してみると、これもオリジナルデータのモデルでは検出できなかったスナップエンドウを検出できるようになってます。
こんな感じの結果となっています。DALL・E mini生成画像を追加することで検出力は若干上がる傾向にあると思います。ですが、過学習っぽい傾向もみられました。これは、DALL・E mini生成画像が似たようなモノが多い影響があるかな?と思います。DALL・E miniのテキスト文章を変えるアレンジがあっても良かったかも😅
従って、ある程度の追加は良いかもしれませんが、大量に追加すると過学習していくのでNGというのが結論です。
ともあれ、DALL・E miniは画期的な技術ですので、まだまだ使い道はあると思います。皆さんもいろいろ試して楽しみましょう👍
今日も良いディープラーニングライフを👍
YOLOv5の様々な使い方について
FarmLブログではYOLOv5の様々な使い方を紹介しています。お時間あれば併せてご覧ください。
- 独自データをつかったYOLOv5の学習方法

- 事前学習済みデータを転移学習したYOLOv5の学習方法

- 遺伝的アルゴリズムを利用したYOLOv5のパラメータ最適化手法

- YOLOv5で物体検出した画像を切り出して学習データにする方法

- YOLOv5で物体検出した作物の数を数える【Object Counter】

- Ultralystics社よりインタビューを受けた内容がブログになりました👍
.webp)

コメント