

YOLOv8はUltralytics社によって開発された物体検出モデルで、2023年2月現在YOLOシリーズの最新モデルとなっています。Ultralytics社は私の大好きなYOLOv5の開発元であり、その後継モデルとなるYOLOv8は期待大です。
今回はオリジナルデータ(スイカ)を準備して、YOLOv8を実装するまでを詳しく解説していこうと思います。また既存モデルとの比較もやってみます👍

スイカはサイズ的には結構大きいのですが、意外と見つけにくい作物です。特に収穫時期では炎天下での作業になります。収穫できそうなスイカが どこに/どのくらい あるのかを事前に把握できると助かる!というモチベーションで実装していきます。
この記事を最後まで読んで実装すると↓のような物体検出をすることができます👍少し大変ですが是非挑戦してみてください!
↓ FarmLブログはYOLOv5についてUltralytics社にインタビューされました!記事が公開されていますので良かったらご覧ください。

YOLOv8の特徴
既に公開されているレビューを見ると、YOLOv8は既存モデルと比較し処理速度が速く、精度が高く、1 つの画像で複数のオブジェクトを検出する能力も高いようです!物体検出のみではなく、分類、セグメンテーションタスクにおいても最先端モデルです。
既存のモデルと比較し、精度および実行時間の両方で優れています。
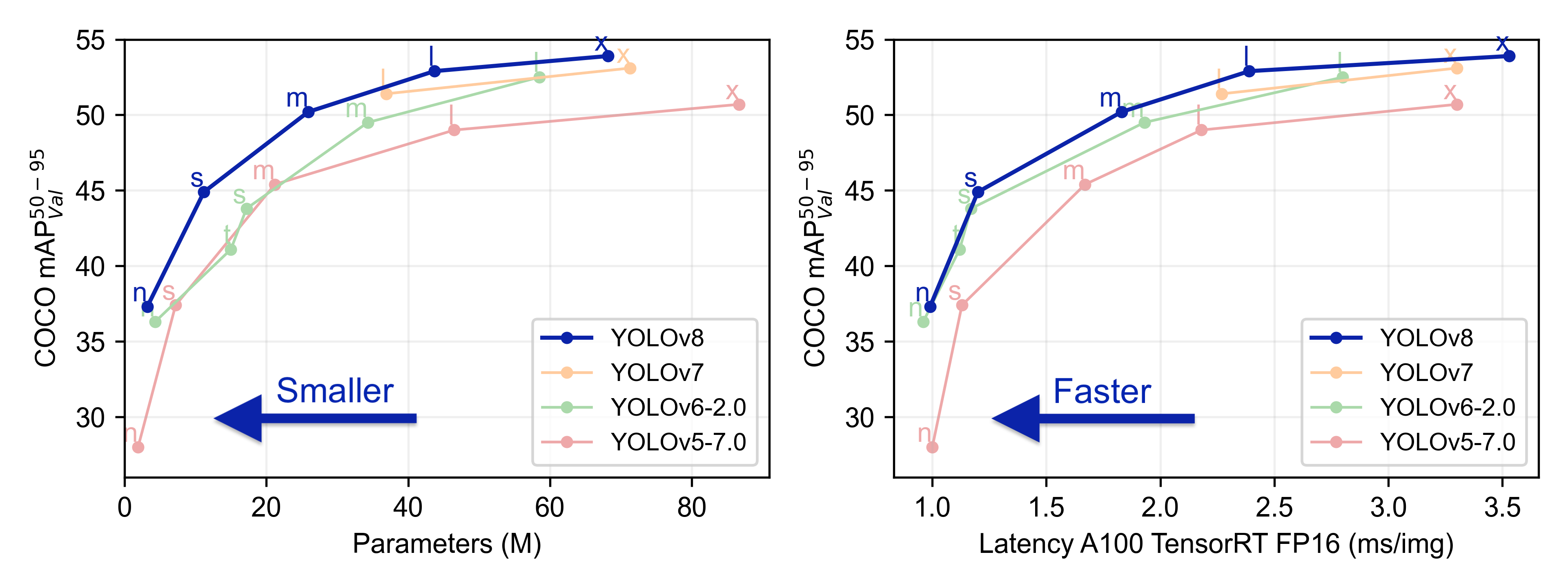
使った感じも変な癖はなく、素直に学習してくれるので、これから物体検出をやってみたい!という方にオススメです。一つだけ、ライセンスGPL-3.0 licenseですので、会社等で使う場合はご注意ください。
YOLOv8の学習準備
それではYOLOv8を実装していきましょう!公式Docがあるので、これを参考に実装していきます!
ローカル環境で実装していきます。スペックは↓
学習環境
GPU搭載したローカルPCの環境で実装していきます。GPU環境のない方はGoogle Colabなどの利用をお勧めします。CPU環境ではしんどいです😂
- OS : Windows 11
- CPU : AMD Ryzen7 5800
- メモリ : 16GB
- GPU : GeForce RTX3070 8GB
CUDAやcuDNN関連は過去の記事と同じ環境で実施していきます。CUDAの環境設定については少し難しいですがこのサイトで詳しく紹介されていますので参照してみてください。
インストール
今回の実装ではPythonとJupyterNotebookを使っていこうと思います。AnacondaもしくはMinicondaをインストールすることでそれらの環境を整えることができます!まずはどちらかをインストールしてください。
インストールしたらAnacondaPromptを起動し、YOLOv8のインストールを実施します。公式Docではいくつかインストール方法が記載されていますが、私は下記の方法で実施しました。
#gitをインストールされていない場合↓を実行
conda install git
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e '.[dev]'ultralyticsという作業フォルダができますので基本的にはここで作業していきます。
PyTorchをインストールしていきます。v1.7以上をインストールしてください。PyTorch公式よりご自身の環境(CUDAのバージョン)に合うモノを選択し、インストールしてください。私の環境ではCUDA:v11.4でしたので↓のようにインストールしました!
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.htmlこれでOKです。あとは実装途中でModuleNotFoundError:みたいのが出たら逐次pip installしていけば大丈夫です。適当ですみません😅
トライアル
インストールできたら試しに動かしてみましょう!下のコードでJupyterNotebookを起動します。
jupyter notebook
起動したら赤枠をクリックいただき、新しいノートブックを作成し↓のコードを実行してみてください。
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8l.yaml") # build a new model from scratch
model = YOLO("yolov8l.pt") # load a pretrained model (recommended for training)
# Use the model
results = model("https://ultralytics.com/images/bus.jpg",save=True) # predict on an imageモデルのダウンロードなどあるので少々時間かかりますがお待ちいただくと、runs\detect\predictフォルダへ物体検出結果が出力されます。
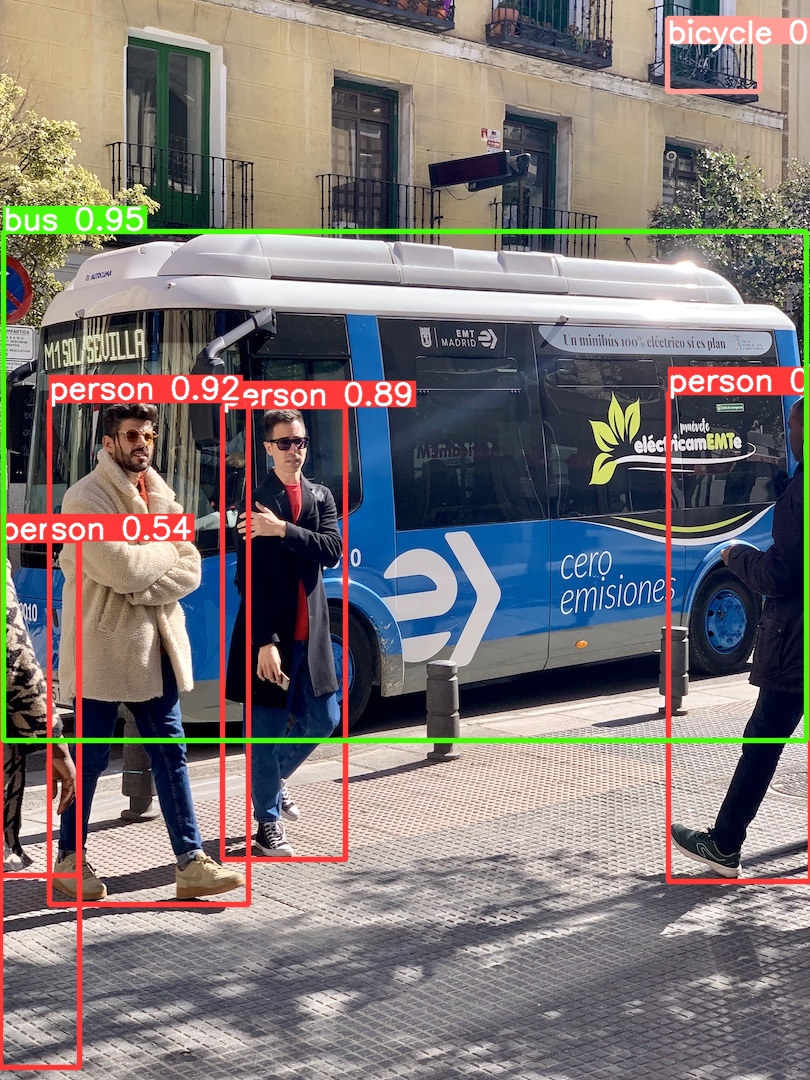
こんな感じでできたと思います。よく見るとベランダに置かれた自転車を検出していて地味にすごいと思いました!既存モデルでは検出できていなかったと思います。
こんな感じでオリジナルデータを学習し、物体検出していきましょう👍
データセットを準備する
データセットを準備していきます。学習データはできるだけ多くのバリエーションを用意してください。作物系だと、時間、天候、葉の茂り具合、被検体までの距離など、様々な影響を受けますので、物体検出したいタイミングで起こりえる事象をよく考えてデータ収集するのがポイントです。
アノテーション
オリジナルのデータ収集が完了したら、アノテーション作業を実施していきます。アノテーションは物体検出したい位置を画像毎にラベリングしていく作業です。YOLOv8ではバウンディングボックスを指定してアノテーションしていきます。
アノテーションツールはいろいろありますが、今回は“labelimg”を使っていきます。
git clone https://github.com/heartexlabs/labelImg.git
cd labelImg
pip install pyqt5 lxml
pyrcc5 -o libs/resources.py resources.qrc
labelImgAnacondaPromptで上記コードで起動すると思います。
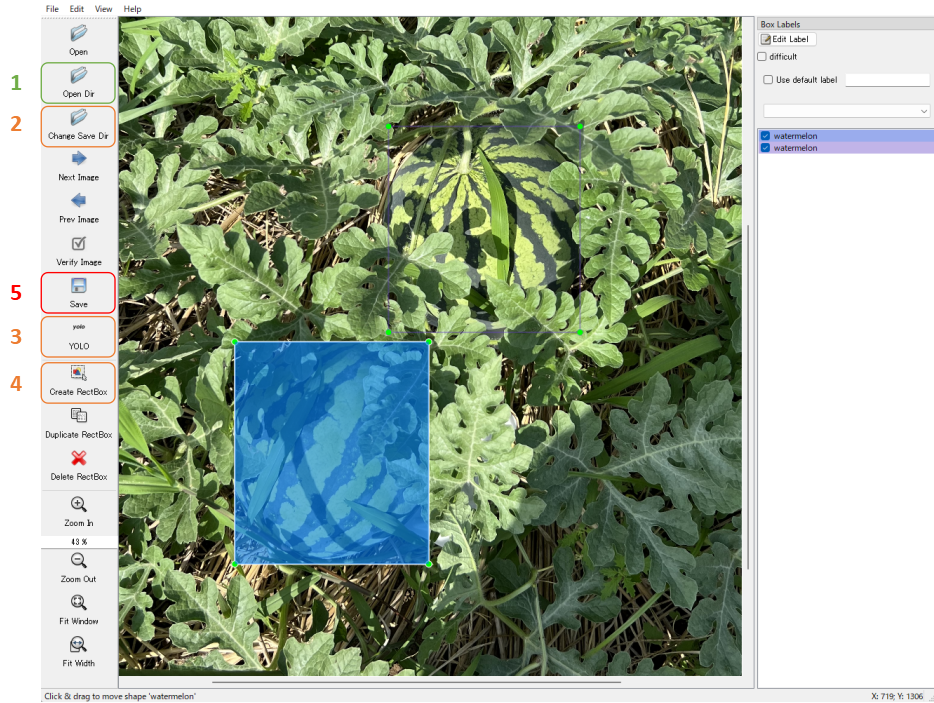
起動すると↑のような画面が出てきて、直感的に作業できると思います。
- 画像データを保存してあるフォルダを指定する
- アノテーションしたデータを保存するフォルダを指定する
- YOLOフォーマットを指定する
- 物体検出したいモノをアノテーションする
- 保存する
上記の作業を全ての画像で実施して下さい。もしどこかでつまずいた場合は、「labelImg 使い方」でググるとたくさん出てきますで調べてみてください😅
保存すると、画像と同じ名称のテキストファイルが生成されます。中身は気にしなくても大丈夫ですが、バウンディングボックス位置と、クラス(分類)がアノテーションされています。(参考)ここで詳しく説明しています。
データの配置
作業フォルダ下へデータを保存するフォルダを作成してください。今回は↓のような配置にしました。
datasets
└── watermelon
├── images
│ ├── train
│ │ ├── train0.jpg
│ │ └── train1.jpg
│ └── val
│ ├── val0.jpg
│ └── val1.jpg
└── labels
├── train
│ ├── train0.txt
│ └── train1.txt
└── val
├── val0.txt
└── val1.txtアノテーションしたデータセットを、学習に使用するtrainデータセットと、検証用のvalデータセットに分割して格納してください。ここでvalデータをケチりたくなりますが、lossを正確に算出できずに過学習の元となるので
train : val = 7 : 3
程度で分割するのが経験的には良さそうです。
.yamlファイルをつくる
YOLOv8ではdataset.yamlファイルでデータセットのパス、クラス数、クラス名称を指定していきます。
作業フォルダ内にテキストファイルを作成し、名前をdataset.yamlへ変更してください。dataset.yamlの中身は↓のように記載します。
# Path
path: ../datasets/watermelon # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
# Classes
nc: 1 # number of classes
names: ['watermelon'] # class namesここのPathはデータの配置で設定したパスを入力してください。Classesについてはご自身のデータセットにおけるクラス数(nc)とクラスの名称(name)を記入してください。
記入できましたらdataset.yamlを作業フォルダ直下へ保存してデータセットの準備は完了です。
YOLOv8でオリジナルデータセットを学習する
いよいよ学習していきます!YOLOv8はPythonコードを数行入力することで簡単に学習できるように設計されています。それではやっていきましょう👍
学習
AnacondaPromptで作業フォルダへ行き、JupyterNotebookを起動してください。下のコードを実行すると学習がスタートします。
from ultralytics import YOLO
model = YOLO("yolov8l.pt")
model.train(data="dataset.yaml", epochs=100, batch=8, workers=4, degrees=90.0)2行目でモデルの初期重みを設定していきます。YOLOv8では↓の表に示すようなモデルを選定できます。表の下に行くにつれて精度は良くなっていきますが、モデルパラメータが増え複雑になってくるので推論速度が落ちます。ご自身の実装環境を考慮し、モデルを選定してください。今回はYOLOv8lを選定しました。
| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed A100 TensorRT (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8n | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
3行目で学習条件を指定しています。dataには作成したyamlファイルのパスを与えます。epochは学習の繰返し回数、batch, workersはミニバッチ数、データの取り出し数なので、ご自身のGPUメモリと相談して設定されるのが良いと思います。
degreesはデータ拡張(Data Augmentation)になります。画像をランダムに0~90度回転させる設定にしています。他にも様々なデータ拡張が可能なように設計されておりますので、ご自身のデータセットで考えられるような拡張を設定してみるとよいと思います。特に過学習している場合に効果ありです。
学習結果の確認
学習結果はruns\detect\trainに格納されます。results.pngを確認すると↓のようなグラフになっていると思います。
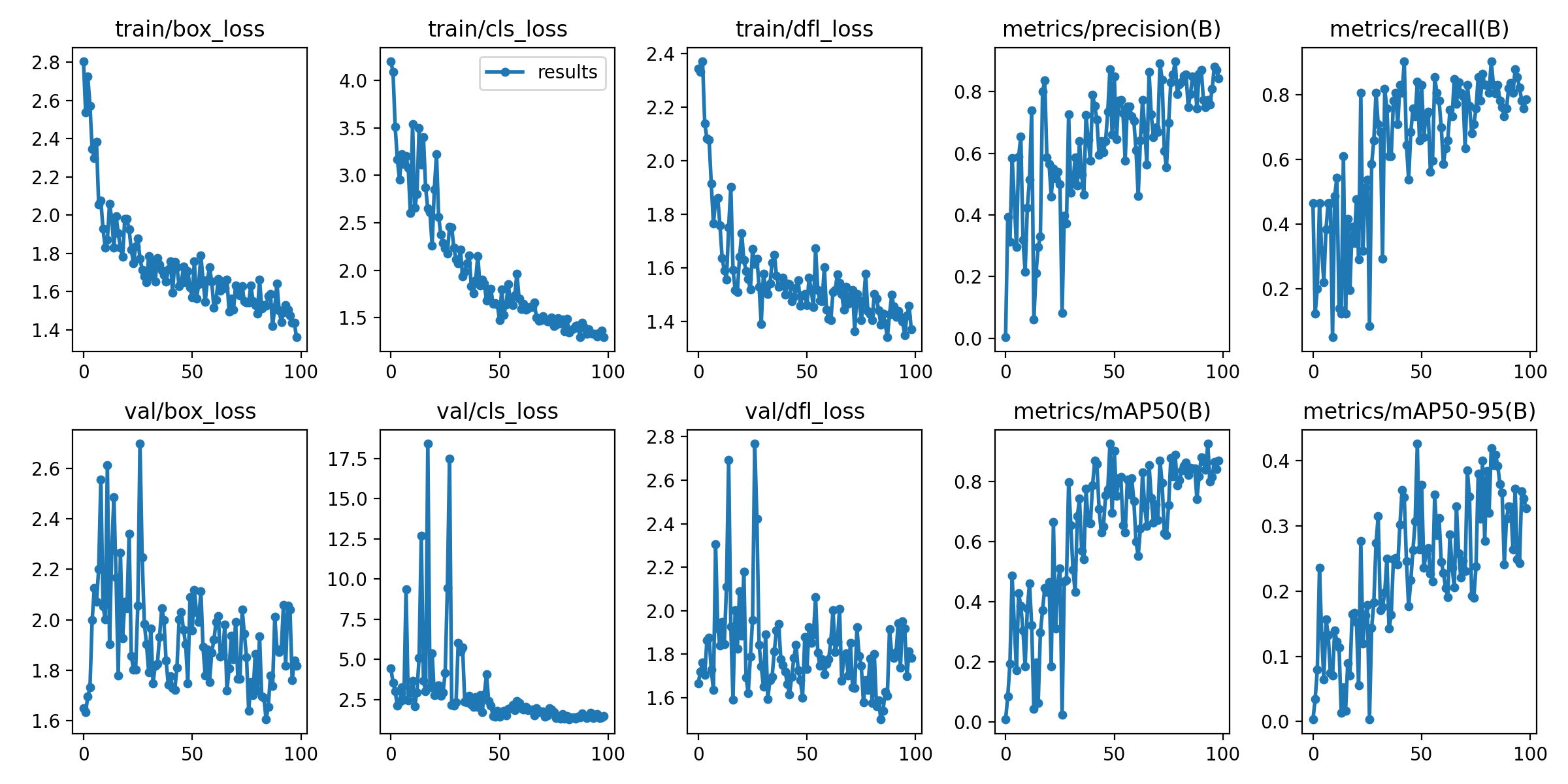
ここで注目すべきは、以下です。
- ****_lossが減少→落ち着いているか
- metrics/mAP50, metrics/mAP50-95の数
lossが下がることで重みが更新されて学習が進んでいることを意味し、落ち着くことで学習が収束したことを意味します。mAPはざっくりいうと精度ですので、この値がモデルの性能となります。
今回は特にチューニングすることなく良く学習できました👍
YOLOv8で学習した重みを使って推論してみる
ここまでお疲れ様でした。いよいよ学習した結果を使って物体検出してみましょう👍
学習の重みデータについて
上で学習した結果にweightsフォルダが格納されていると思います。その中のbest.pt, last.ptが学習によって得られた重みデータです。bestは学習中において最も精度が良かったステップでの重みデータ、lastは最終の重みデータとなります。今回はlast.ptを用いて推論してみます。
推論したいデータを作業フォルダ内に格納
作業フォルダ下に”predict”というフォルダをつくってファイルを格納していきます。静止画(.jpg,.png)などに加え、動画(.mov,.mp4)、Youtube(https://youtu.be/***)でもOKです。(他の形式もサポートしているかと思いますが、試していません😅)
JupyterNotebookでコードを実行
JupyterNotebookで下のコードを実行してください。
model = YOLO('./runs/detect/train/weights/last.pt')
model("./predict",save=True, conf=0.2, iou=0.5)1行目は学習した重みデータのパスを指定しモデルを読み込んでいます。2行目で推論を実行していますが、”save=True”を忘れないでください。推論結果を保存する引数です。conf、iouはそれぞれバインディングボックスの表示閾値となっています。引数の詳細や、他の引数については知りたい場合は、公式Docを参照してみてください。
実行するとruns\detect\predictフォルダが作成され、推論結果が保存されると思います。元画像と比較すると↓の感じです。




いい感じで検出できております🚀🚀🚀
動画は👇の感じです。人の目では一見わからないですが、ちゃんとスイカを検出できています!ちなみに学習に使用していない動画で検証していますよ。ズルしてないです😋
ここまでがYOLOv8の実装です。みなさん良い物体検出モデルができましたでしょうか。面白いモデルができたら是非教えてください😄
既存モデルとの比較
最後にYOLOv8のモデル精度を既存モデルと比較してみます。データセットはFarmLブログオリジナルのスナップエンドウの画像を用い、モデルのパラメータは同じくらいに合わせてあります。
Precision/Recall/mAPの比較
| Model | Precision | Recall | mAP50 |
|---|---|---|---|
| YOLOv5 | 0.84 | 0.79 | 0.84 |
| YOLOv7 | 0.83 | 0.79 | 0.83 |
| YOLOv8 | 0.81 | 0.81 | 0.83 |
FarmLブログのデータセットでは大差なしの結果でしたが、YOLOv5/YOLOv7ではパラメータチューニングを実施しているので、YOLOv8はまだ伸び代があるかもしれません。今後確認していきたいです。
動画比較は↓の感じです。
FarmL BLOGで実装してきたYOLOモデルについて
FarmLブログではYOLOv5の様々な使い方を紹介しています。お時間あれば併せてご覧ください。
独自データをつかったYOLOv5の学習方法

事前学習済みデータを転移学習したYOLOv5の学習方法

遺伝的アルゴリズムを利用したYOLOv5のパラメータ最適化手法

YOLOv5で物体検出した画像を切り出して学習データにする方法

YOLOv5で物体検出した作物の数を数える【Object Counter】

YOLOv6でオリジナルデータの物体検出をやってみる

YOLOv7でオリジナルデータを物体検出する

YOLOv7にオブジェクトカウンターを付ける

Ultralystics社よりインタビューを受けた内容がブログになりました👍

コメント
当サイトを見て物体検出に興味が湧き、
自作データセットにて自動検出を試みています。YOLOv8はYOLOv5みたく、遺伝的アルゴリズムを用いたハイパラメーターチューニングはできるのでしょうか?
すぐるさん
コメントありがとうございます。興味を持っていただきうれしく思います。
物体検出は直感的に分かりやすいAIですので構築していて楽しいですよね。
さて、YOLOv8のハイパーパラメータチューニングですが、私は試せていないのですがRay Tuneを使った方法があるようです。
下記ドキュメントを参考に実行してみてください!
https://docs.ultralytics.com/integrations/ray-tune/